
Ứng dụng mô hình ngôn ngữ lớn để phân tích sắc thái bài viết hỗ trợ giám sát không gian mạng
An toàn thông tin - Ngày đăng : 09:35, 18/12/2024
Ứng dụng mô hình ngôn ngữ lớn để phân tích sắc thái bài viết hỗ trợ giám sát không gian mạng
Tổng quan về các mô hình ngôn ngữ lớn trong xử lý ngôn ngữ tự nhiên (NLP), đặc biệt nhấn mạnh đến mô hình Transformer và các mô hình phát triển từ nó như BERT, GPT.
Tóm tắt:
- Tổng quan về các mô hình ngôn ngữ lớn trong xử lý ngôn ngữ tự nhiên (NLP), đặc biệt nhấn mạnh đến mô hình
Transformer và các mô hình phát triển từ nó như BERT, GPT.
- Phát triển mô hình Vistral_sentiQ: Tác giả đề xuất mô hình Vistral_sentiQ, được tinh chỉnh từ mô hình Vistral-7B, để
phân tích sắc thái văn bản tiếng Việt.
- Dữ liệu sử dụng: Tập dữ liệu gồm 6.000 bài viết (tích cực, tiêu cực, trung lập) được sử dụng để huấn luyện và kiểm thử mô hình.
- Kiểm tra độ chính xác: Mô hình Vistral_sentiQ đạt độ chính xác 90,04% trên tập kiểm thử, cao hơn so với mô hình
gốc Vistral-7B.
- Kết luận: Mô hình Vistral_sentiQ được áp dụng thành công trong giám sát không gian mạng, chứng minh tính hiệu
quả vượt trội.
Giới thiệu tổng quan về một số mô hình ngôn ngữ lớn trong xử lý ngôn ngữ tự nhiên
Thế giới đã trải qua 4 cuộc Cách mạng công nghiệp (CMCN) gồm: 1) cuộc cách mạng cơ giới hóa từ động cơ hơi nước; 2) cuộc cách mạng cơ khí hóa với sự phát minh ra điện; 3) cuộc cách mạng tự động hóa với sự ra đời của máy tính; 4) và cuộc cách mạng thứ 4 là kết hợp của cuộc cách mạng thứ 3 và các hệ thống không gian mạng.
Cuộc cách mạng lần thứ 4 hiện đang bùng nổ trên toàn thế giới với sự kết hợp của kết nối vạn vật (IoT), trí tuệ nhân tạo (Artificial Intelligence) trên nền tảng dữ liệu lớn, máy tính hiệu năng cao, các thuật toán phát triển.
Trong cuộc Cách mạng 4.0, xử lý ngôn ngữ tự nhiên (NLP) là một lĩnh vực của khoa học máy tính và AI liên quan đến sự tương tác giữa máy tính và con người trong ngôn ngữ tự nhiên như văn bản, thoại. Mục tiêu của NLP là cho phép các máy tính hiểu ngôn ngữ như con người. Một số ứng dụng của NLP có thể được sử dụng như trợ lý ảo, nhận dạng giọng nói, phân tích sắc thái, tự động tóm tắt văn bản, dự đoán chiều hướng, tìm kiếm thông tin liên quan, dịch máy...
Quá trình nghiên cứu về NLP đã được thực hiện từ những năm 1950. Nhưng do sự giới hạn về khả năng tính toán của các máy tính hiệu năng cao, và dữ liệu lớn, nên lĩnh vực nghiên cứu này đã bị đóng băng một thời gian dài. Cho đến cuối những năm 1980, một cuộc cách mạng trong xử lý ngôn ngữ tự nhiên ra đời dựa trên các thuật toán máy học cho xử lý ngôn ngữ tự nhiên.
Từ những năm 2010, các thuật toán máy học sâu mạng nơ-ron đã trở nên phổ biến trong xử lý ngôn ngữ tự nhiên, cộng với đó là sự tồn tại của dữ liệu lớn hiện nay, các máy tính công suất lớn, từ đó các ứng dụng cho xử lý ngôn ngữ tự nhiên phát triển nhanh chóng không chỉ trong các sản phẩm thương mại và còn phục vụ cho các tổ chức chính phủ, quân đội.
Các mô hình ngôn ngữ lớn (Large Language Model - LLM) gần đây đã chứng minh khả năng rất lớn bao gồm xử lý ngôn ngữ tự nhiên NLP, dịch ngôn ngữ, sinh văn bản, hỏi đáp... Ngoài ra, các mô hình LLM là một phần mới, then chốt của xử lý ngôn ngữ trên máy tính, mà có khả năng hiểu các mẫu ngôn ngữ phức tạp và đưa ra các câu trả lời mạch lạc và phù hợp cho tình huống [1, 2].

Sự tiến bộ đáng kể trong các hệ thống LLM xuất hiện khi kiến trúc Transformer được đưa ra trong nghiên cứu [3]. Mô hình Transformer được xây dựng dựa trên cơ chế tự chú ý, mà cho phép thực hiện song song và hiệu quả sự phụ thuộc trong một dải rộng. Hơn nữa, mô hình Transformer là cơ sở để xây dựng các mô hình khác như mô hình Bidirectional Encoder Representations from Transformers (BERT) của Google, mô hình Generative Pre-trained Transformer (GPT) của OpenAI mà thực hiện xuất sắc các nhiệm vụ trong lĩnh vực ngôn ngữ khác nhau.
Trong nghiên cứu [4], các tác giả đã đưa ra mô hình LlaMA là một bộ các mô hình ngôn ngữ nền tảng từ 7 tỉ (7B) đến 65 tỷ (65B) tham số. Mô hình LlaMA được huấn luyện dựa trên hàng nghìn tỉ tokens đã chỉ ra rằng các mô hình mới nhất có thể được huấn luyện sử dụng các tập dữ liệu có sẵn công khai mà không cần dùng đến các bộ dữ liệu độc quyền và không thể truy cập được. Đặc biệt, mô hình LlaMA-13B vượt trội GPT-3 (175B) ở hầu hết các khía cạnh.
Gần đây, Albert Q. Jiang và các cộng sự [5] đã đề xuất mô hình Mistral 7B - mô hình ngôn ngữ 7 tỉ tham số được thiết kế cho chất lượng và hiệu quả vượt trội. Mô hình Mistral 7B vượt trội so với mô hình mở tốt nhất LlaMA 2 với 13B tham số trên tất cả các khía cạnh được đánh giá và vượt trội so với mô hình LlaMA 1 với 34B tham số về mặt lý thuyết, toán học và tạo mã. Mô hình Mistral 7B đưa ra Sự chú ý truy vấn được nhóm (Grouped-query attention - GQA) cho sự suy luận nhanh hơn, cùng với sự chú ý cửa sổ trượt để xử lý hiệu quả các chuỗi có chiều dài tùy ý với chi phí suy luận được giảm.
Nghiên cứu [6] đã đưa ra mô hình ngôn ngữ lớn cho tiếng Việt - Vistral-7B được phát triển từ mô hình Mistral 7B bằng cách huấn luyện và tinh chỉnh liên tục sử dụng tập dữ liệu đa dạng. Cụ thể, các bước để phát triển mô hình Vistral bao gồm: Mở rộng từ vựng cho mô hình Mistral 7B để hỗ trợ tiếng Việt; Thực hiện việc huấn luyện liên tục mô hình Mistral trên tập dữ liệu đa dạng các văn bản tiếng Việt mà đã được làm sạch và loại bỏ trùng lặp một cách cẩn thận; Thực hiện tinh chỉnh có giám sát cho mô hình sử dụng tập dữ liệu đa dạng với nhiều chủ đề.
Trong bài báo này, chúng tôi đề xuất mô hình ngôn ngữ lớn Vistral_sentiQ được tinh chỉnh dựa trên mô hình Vistral-7B và sử dụng tập dữ liệu tiếng Việt cho bài toán phân tích sắc thái văn bản. Tập dữ liệu được xây dựng có kích thước 3MB gồm 6.000 văn bản được thu thập từ nhiều nguồn, được chia thành 3 tập với các nhãn tích cực, tiêu cực, trung tính.

Xây dựng mô hình ngôn ngữ lớn để phân tích sắc thái văn bản
Cấu hình tham số của mô hình
Kiến trúc của mô hình Vistral_sentiQ dựa trên kiến trúc transformer [3]. Các tham số của mô hình được trình bày trong Bảng 1. Kích thước của tập từ điển được sử dụng là 38369, mà lớn hơn so với tập từ điển của mô hình Mistral 7B, và tương đương với tập từ điển của mô hình gốc Vistral-7B.
Tập dữ liệu
Các tác giả đã xây dựng tập dữ liệu gồm 6.000 bài viết bao gồm 2.000 bài viết được gán nhãn tích cực được thu thập từ các trang MXH của lực lượng BCĐ 35, lực lượng 47; 2.000 bài viết được gán nhãn tiêu cực được thu thập từ các trang MXH của lực lượng nói xấu, bôi nhọ lãnh đạo, xuyên tạc đường lối chủ trương chính sách của Đảng...; và 2.000 bài viết được gán nhãn trung lập là các bài viết đưa tin.
Các bài viết sau khi thu thập, được thực hiện gán nhãn thủ công để đảm bảo tính đúng, sạch của dữ liệu. Ngoài ra, để đảm bảo tính khách quan trong đánh giá sắc thái của các bài viết thu thập được, chúng tôi cũng sử dụng một số công cụ có sẵn, mã nguồn mở mô hình ngôn ngữ lớn như Vistral-7B để đánh giá nhãn sắc thái các bài viết và tham chiếu với gán nhãn thủ công. Từ đó, các bài viết được lọc và gán nhãn cho quá trình huấn luyện đảm bảo tính đúng, sạch.
Hình 1 chỉ ra quy trình xây dựng mô hình phân tích sắc thái văn bản Vistral_sentiQ dựa trên quá trình tinh chỉnh mô hình ngôn ngữ lớn Vistral-7B [6] sử dụng phương pháp LoRA. Quá trình xây dựng mô hình gồm quá trình tinh chỉnh mô hình (Finetuning) Vistral-7B và quá trình dự đoán. Dữ liệu đầu vào của quá trình tinh chỉnh là các dữ liệu văn bản và các nhãn tương ứng với sắc thái phân loại gồm tích cực, tiêu cực và trung lập.
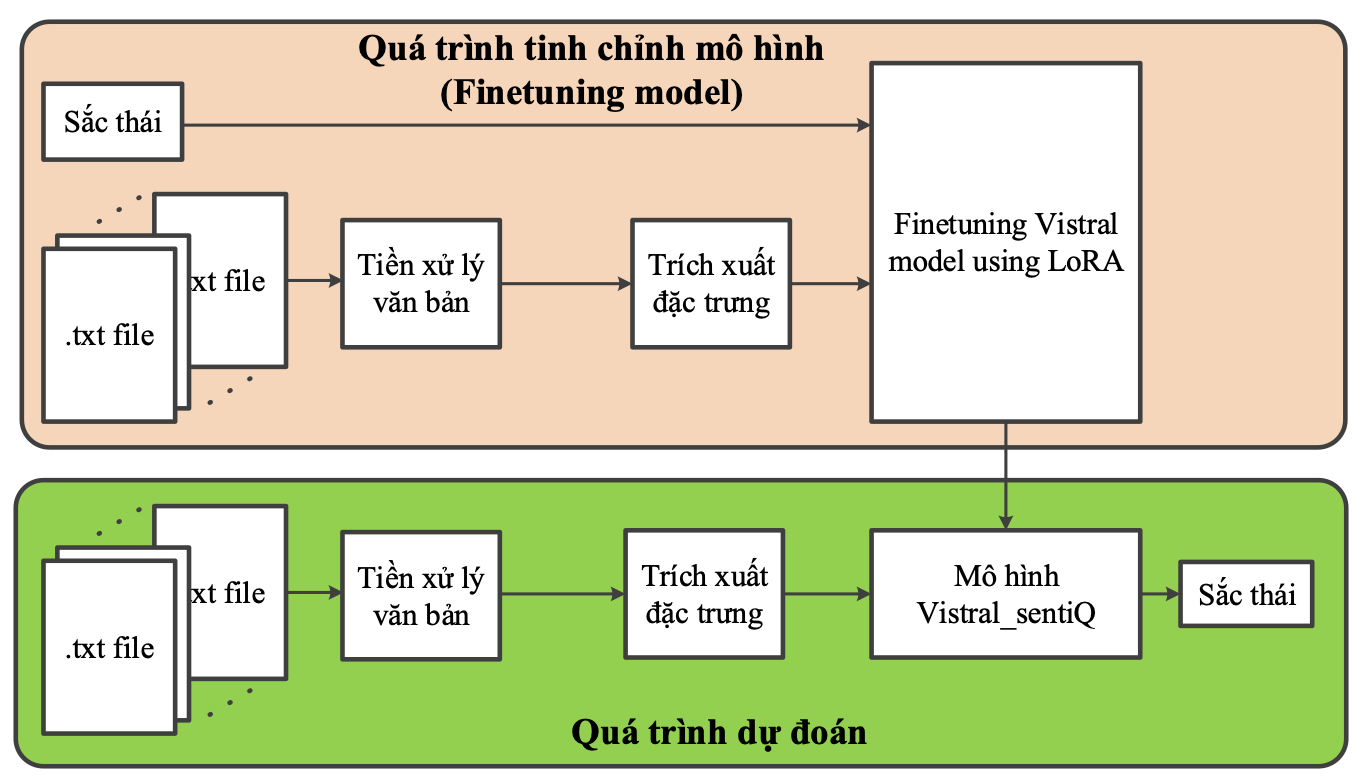
Đầu tiên, dữ liệu thu thập được sẽ trải qua quá trình làm sạch, loại bỏ nhiễu, chuẩn hóa, tách từ, loại bỏ từ vô nghĩa. Đây là bước tiền xử lý dữ liệu. Tiếp theo, dữ liệu của từng văn bản sẽ được chuyển thành dữ liệu dạng ma trận số sử dụng thuật toán Embedding; Quá trình này là trích xuất đặc trưng của dữ liệu.
Sau đó, ta tiến hành gán nhãn cho dữ liệu thuộc một trong 3 nhãn là tích cực, tiêu cực và trung tính. Mô hình Vistral-sentiQ được tinh chỉnh dựa trên mô hình Vistral-7B sử dụng giải pháp LoRA và tập dữ liệu mới đã được trình bày ở trên.
Bước cuối cùng trong quá trình này là đánh giá mô hình phân tích sắc thái Vistral-sentiQ đã được xây dựng bằng cách dự đoán sắc thái cho tập dữ liệu mới sử dụng mô hình đã được tinh chỉnh, qua đó đánh giá độ chính xác của mô hình.
Sau khi đã xây dựng được thuật toán cho mô hình, chúng ta tiến hành kiểm tra độ chính xác của mô hình bằng cách cho mô hình phân tích đánh giá nội dung tập dữ liệu đã được chuẩn bị. Từ kết quả thu được ta có được độ chính xác của mô hình và qua đó có những bước cải thiện thuật toán.
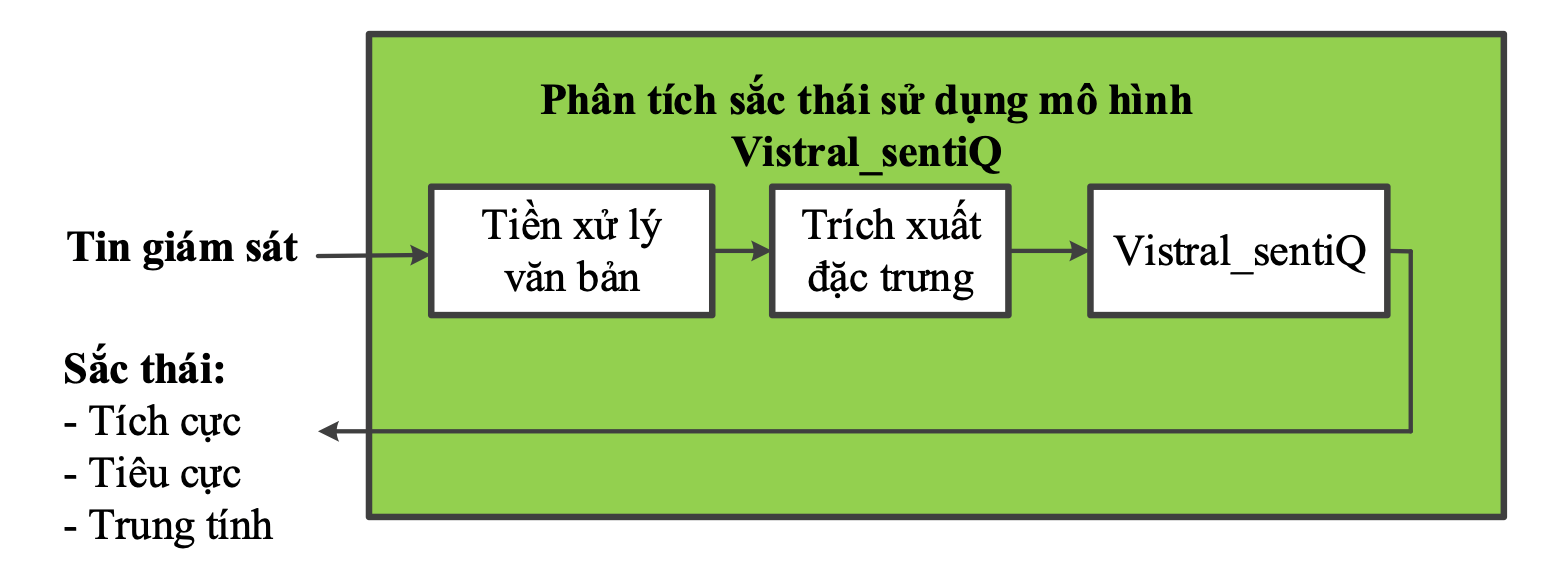
Hình 2 chỉ ra quá trình phân tích đánh giá nội dung cho dữ liệu mới đầu vào sử dụng mô hình đã được huấn luyện. Các dữ liệu đầu vào được thực hiện tiền xử lý và trích xuất đặc trưng dữ liệu, tương tự như bước 1 và 2 trong quá trình tinh chỉnh mô hình. Sau đó, các véc-tơ thuộc tính dữ liệu được đưa vào đầu vào của mô hình Vistral_sentiQ đã tinh chỉnh để đánh giá sắc thái, và đầu ra sẽ là sắc thái tương ứng với nội dung văn bản đầu vào.
3. Đánh giá độ chính xác của mô hình Vistral_sentiQ
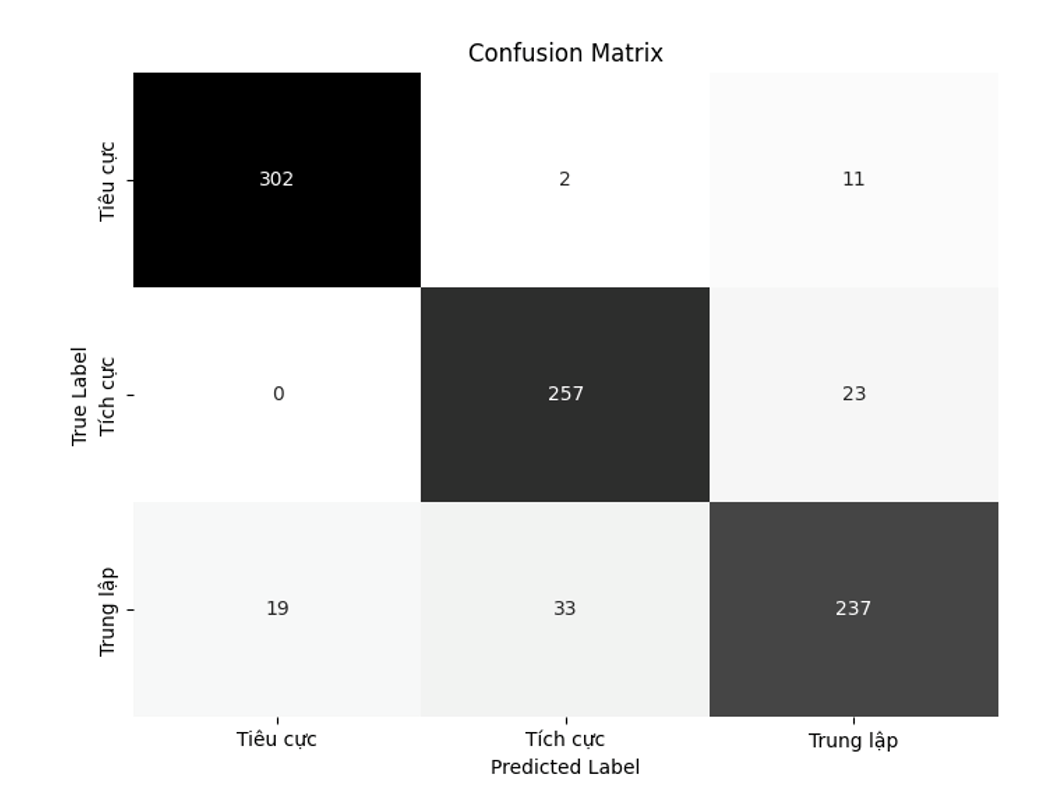
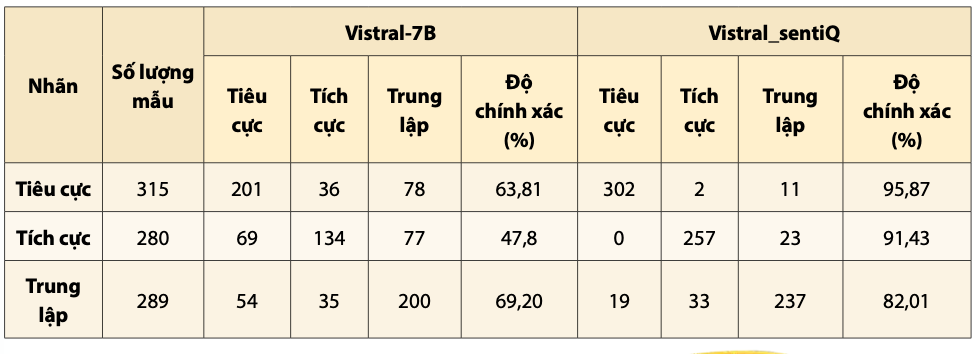
Sau khi thử nghiệm với tập kiểm thử gồm 884 mẫu test, kết quả độ chính xác trung bình của mô hình là 90,04% với ma trận confusion matrix thu được như Hình 3. Bảng 2 chỉ ra ví dụ sử dụng mô hình Vistral_sentiQ phân tích sắc thái văn bản, trong đó Instruction bao gồm định nghĩa sắc thái Tích cực, Tiêu cực, Trung lập của bài viết, cùng với yêu cầu phân tích sắc thái và nội dung bài viết. Sau Instruction là kết quả sắc thái của bài viết.


4. Kết luận
Trong bài viết, các tác giả đã xây dựng mô hình phân tích sắc thái Vistral_sentiQ cho tiếng Việt gồm nhãn tích cực, tiêu cực và trung tính dựa trên việc tinh chỉnh mô hình Vistral-7B. Kết quả thực nghiệm đã chỉ ra rằng, sau khi được tinh chỉnh mô hình Visral_sentiQ có độ chính xác 90,4% mà cao hơn so với mô hình Vistral-7B với cùng tập dữ liệu. Mô hình này đã được đưa vào sử dụng trong các hệ thống Cthực tế và đã chứng minh được tính hiệu quả trong việc hỗ trợ giám sát không gian mạng.
Tài liệu tham khảo:
1. Mohaimenul Azam Khan Raiaan, Md. Saddam Hossain Mukta, Kaniz Fatema, Nur Mohammad Fahad, Sadman Sakib, Most. Marufatul Jannat Mim, Jubaer Ahmad, Mohammed Eunus
Ali, and Sami Axzam, A review on large language models: architectures, applications, taxonomies, open issues and challenges.
2. Humza Naveed, Asad Ullah Khan, Shi Qiu, Muhammad Saqib, Saeed Anwar, Muhammad Usman, Naveed Akhtar, Nick Barnes, Ajmal Mian, A comprehensive overview of large language models, Elsevier, April 11, 2024.
3. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia
Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
4. Hugo Touvron and Thibaut Lavril and Gautier Izacard and Xavier Martinet and Marie-Anne Lachaux and Timothe
Lacroix and Baptiste Rozire and Naman Goyal and Eric Hambro and Faisal Azhar and Aurelien Rodriguez and
Armand Joulin and Edouard Grave and Guillaume Lample, LLaMA: open and efficient foundation language models,
27 Feb, 2023.
5. Albert Qiaochu Jiang and Alexandre Sablayrolles and Arthur Mensch and Chris Bamford and Devendra Singh Chaplot and Diego de Las Casas and Florian Bressand and Gianna Lengyel and Guillaume Lample and Lucile Saulnier and L’elio Renard Lavaud and Marie-Anne Lachaux and Pierre Stock and Teven Le Scao and Thibaut Lavril and Thomas Wang and Timothe Lacroix and William El Sayed, Mistral 7B, ArXiv, 2023.
6. https://huggingface.co/Viet-Mistral/Vistral-7B-Chat
7. Minh Thuan Nguyen and Khanh-Tung Tran and Nhu-Van Nguyen and Xuan-Son Vu, ViGPTQA
- State-of-the-Art LLMs for Vietnamese Question Answering: System Overview, Core Models Training, and Evaluations, Conference on Empirical Methods in Natural Language
Processing, 2023.
(Bài đăng ấn phẩm in Tạp chí TT&TT số 9 tháng 9/2024)