
Rất dễ dàng để thu thập dữ liệu, ra quyết định dựa trên dữ liệu mới là điều khó khăn.
Ngày nay, con người có quyền truy cập vào một lượng dữ liệu khổng lồ, và lượng dữ liệu này chỉ có chiều hướng tăng lên từng ngày. Điều này chủ yếu là do sự gia tăng trong khả năng thu thập dữ liệu và tăng sức mạnh tính toán để lưu trữ lượng dữ liệu được thu thập này. Tuy nhiên, thu thập dữ liệu là một chuyện, nhưng việc làm cho dữ liệu trở nên có ý nghĩa lại là vấn đề hoàn toàn khác. Việc đạt được nhận thức sâu sắc từ dữ liệu nên nhanh chóng và dễ dàng, và kết quả thu được nên mạch lạc và dễ dàng giải thích. H2O cung cấp một nền tảng duy nhất giúp cả việc ghi điểm và mô hình hóa thông qua mô hình dự đoán nhanh hơn và tốt hơn.
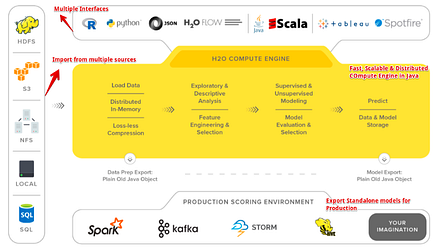
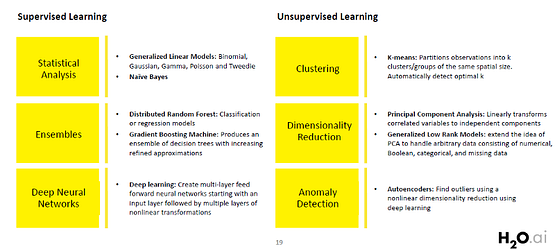
H2O là một nền tảng bộ nhớ trong để học máy phân tán và có thể mở rộng. H2O là tên của sản phẩm và của công ty (H2O.ai) phát hành nó. Nó hoàn toàn là nguồn mở và sử dụng các giao diện quen thuộc như R, Python, Scala, Java, JSON và thậm chí là giao diện web. Phiên bản mới nhất của H2O có tên gọi H2O-3, và nó hoạt động trơn tru với nhiều công nghệ dữ liệu lớn như Spark và Hadoop. Ngoài ra, H2O hỗ trợ rất nhiều thuật toán thường được sử dụng của Machine Learning, chẳng hạn như GBM, Random Forest, Deep Neural Networks, Word2Vec, Stacked Ensembles và một số thuật toán khác.
H2O FLow
H2O Flow là một giao diện độc lập với H2O. Người dùng có thể sử dụng trình duyệt của mình để trỏ đến localhost và sau đó giao tiếp trực tiếp với công cụ H2O mà không phải đối phó với Python hoặc R, hoặc bất kỳ ngôn ngữ lập trình nào khác. Nó là một công cụ tuyệt vời để nhanh chóng mô hình hóa dữ liệu bằng cách sử dụng tất cả các thuật toán tuyệt vời có sẵn trong H2O, thông qua giao diện web đơn giản mà không cần lập trình. Người dùng có thể dễ dàng chạy một mạng thần kinh, GBM, GLM, K-means, Naive Bayes, v.v... chỉ với một vài cú nhấp chuột.
Flow là giao diện dựa trên web của H2O và là cách tuyệt vời để người dùng mới bắt đầu và tìm hiểu tất cả các tính năng và thuật toán có sẵn mà H2O cung cấp.
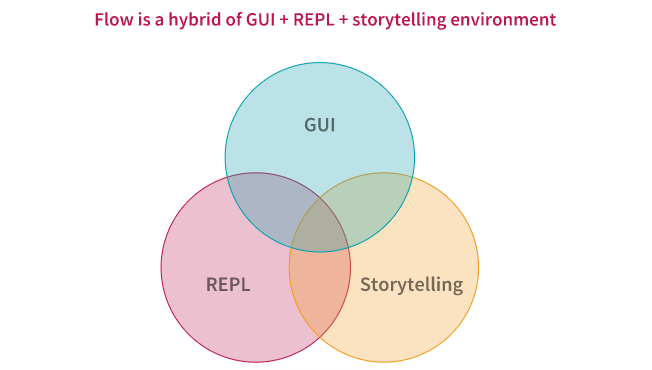
Flow có thể được coi là sự kết hợp của GUI REPL và môi trường kể chuyện, để phân tích dữ liệu khám phá và học máy, với khả năng ghi/phát lại kịch bản để có thể tái lập kịch bản. Bài viết là hướng dẫn sử dụng chi tiết về H2O Flow.
Thiết lập
H2O chạy trên Java, điều kiện tiên quyết để nó hoạt động. H2O sử dụng Java 7 trở lên, người dùng có thể tải H2O tại trang tải xuống Java.

Tải xuống H2O từ liên kết này và làm theo các bước dưới đây.
Sau khi cài đặt và chạy, hãy trỏ trình duyệt tới http:/ localhost:54321 để truy cập giao diện Flow.
Giao diện
Nếu người dùng đã làm việc với Jupyter Notebook, giao diện của Flow sẽ trở nên quen thuộc với bạn. Giống như trong Notebook Jupyter, Flow cũng có hai chế độ Cell Mode: edit (chỉnh sửa) và command (lệnh). Truy cập liên kết này để hiểu thêm về Cell Mode.
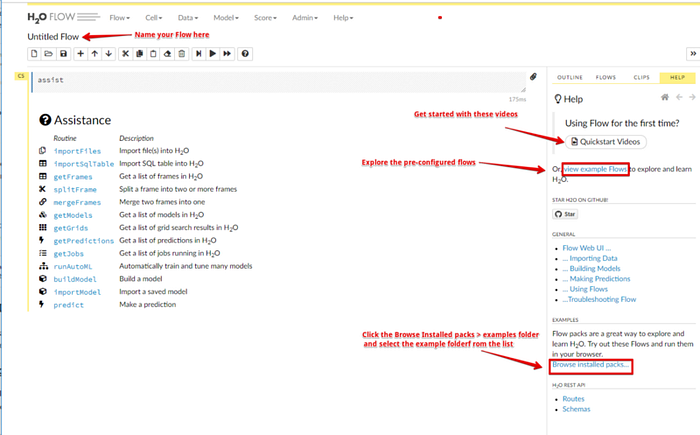
Hoạt động
Flow gửi các lệnh đến H2O như một chuỗi các ô thực thi. Các ô có thể được sửa đổi, sắp xếp lại hoặc lưu vào thư viện. Trong Flow, người dùng có thể xen kẽ giữa các ô văn bản và các ô thực thi nơi người dùng có thể nhập hoặc yêu cầu H2O tạo một CoffeeScript, có thể chạy theo chương trình và chia sẻ giữa những người dùng. Để thực thi một ô, nhấn tổ hợp phím CTRL ENTER hoặc sử dụng biểu tượng Run trên thanh công cụ.
Bây giờ, hãy sử dụng H2O trong Flow UI để xử lý vấn đề Machine Learning và xem xét các tính năng khác nhau của nó một cách chặt chẽ.
Dự đoán xu hướng khách hàng sử dụng H2O
Dự đoán xu hướng khách hàng là một vấn đề được biết đến trong không gian của Quản lý quan hệ khách hàng (CRM - Customer Relationship Management) và là một yếu tố quan trọng của các chiến lược tiếp thị hiện đại. Giữ chân khách hàng là điều rất quan trọng đối với các tổ chức và người dùng sẽ thấy H2O có thể đóng vai trò quan trọng như thế nào trong luồng khoa học dữ liệu, bằng cách nhanh chóng tạo ra các mô hình dự đoán và sau đó sử dụng thông tin chi tiết để tăng khả năng giữ chân khách hàng.
Bộ dữ liệu được sử dụng thuộc về 2009 KDD Cup Challenge. Bộ dữ liệu này cũng có thể được truy cập trong Examples (Ví dụ)> Browse installed packs (Các gói cài đặt) > examples > KDDCup 2009_Churn.flow trong giao diện Flow. Ngoài ra, người dùng có thể sử dụng các liên kết sau để truy cập dữ liệu đào tạo và xác nhận tương ứng:
- Training Data (Dữ liệu đào tạo)
- Validation data (Dữ liệu xác nhận)
Dưới đây là kênh Flow mà người dùng sẽ sử dụng để thực hiện đào tạo và dự đoán.

Importing data (Nhập dữ liệu) > Parsing data (Phân tích dữ liệu) > Inputting data (Dữ liệu đầu vào) > Model building (Xây dựng mô hình) > Interpreting data (Diễn giải dữ liệu) > Prediction (Dự đoán).
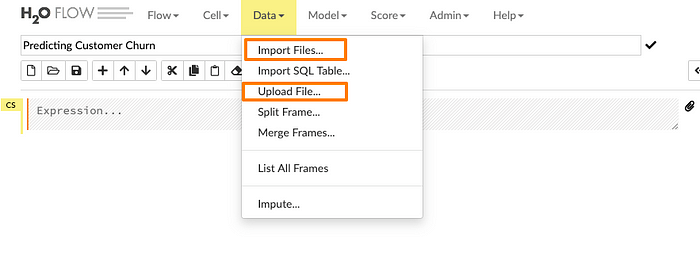
Nhập/Tải dữ liệu
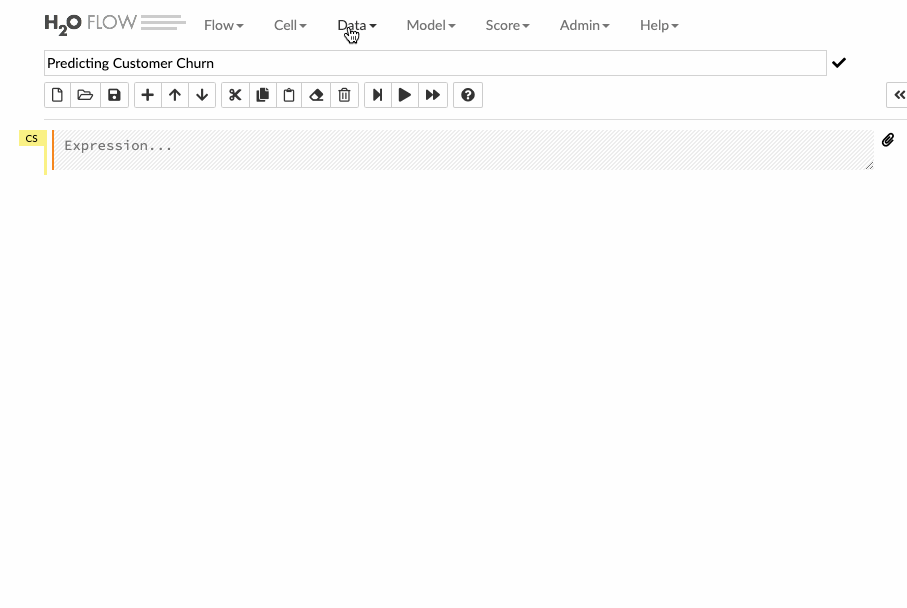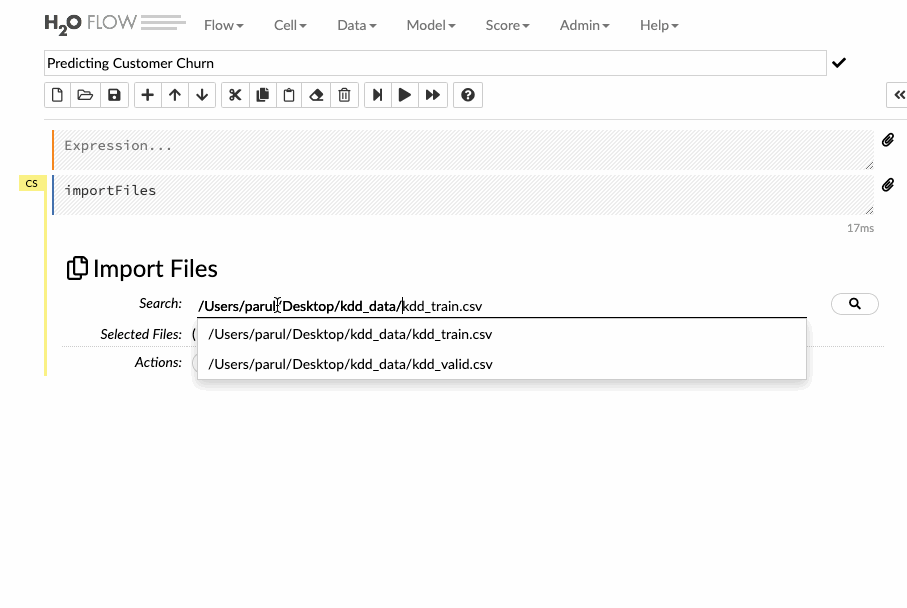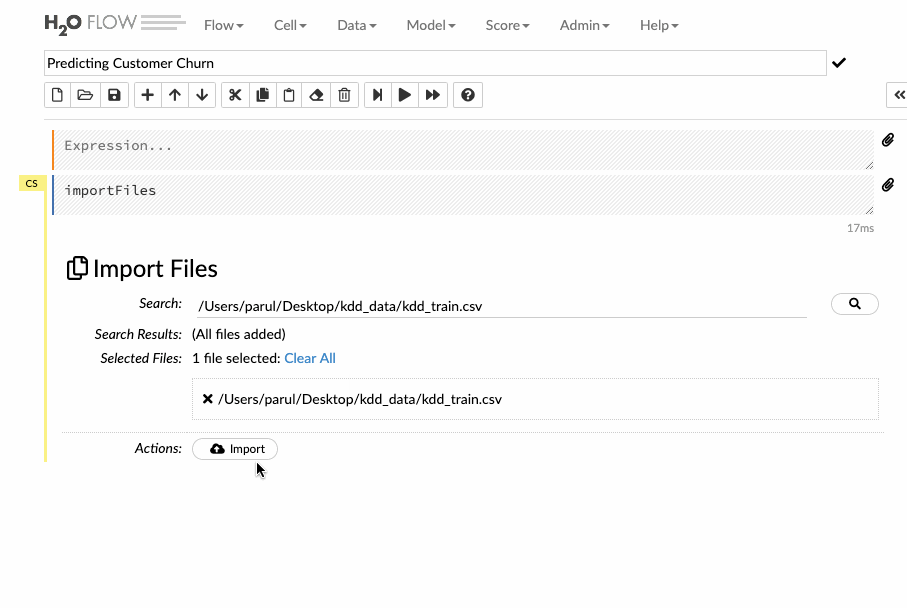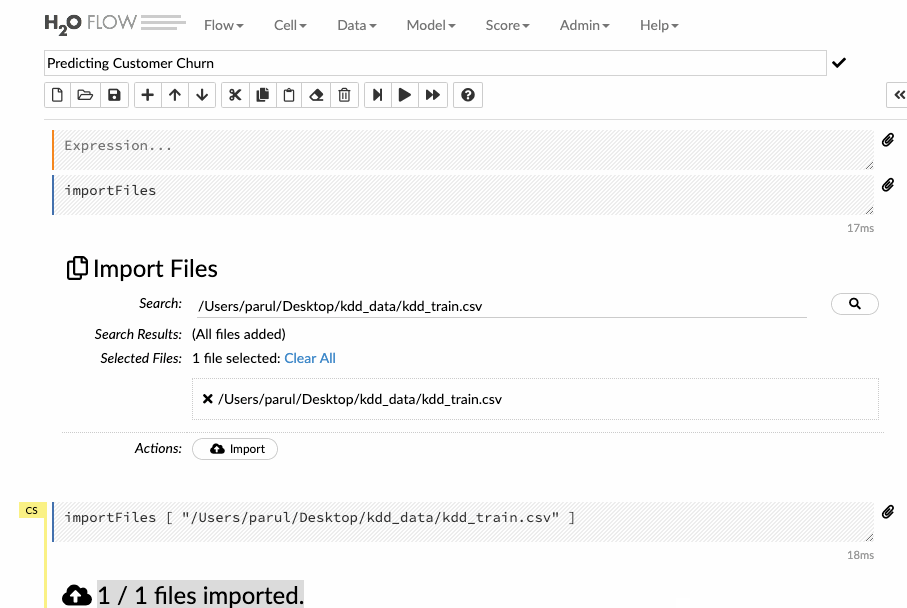
Nhập đường dẫn tệp trong trường nhập tự động hoàn thành và nhấn Enter. Chọn tệp từ kết quả tìm kiếm và xác nhận nó bằng cách nhấp vào liên kết Add all (Thêm tất cả). Người dùng cũng có thể tải lên một tệp cục bộ hoặc có thể trực tiếp đề cập đến url của tập dữ liệu.
Hãy xem làm thế nào để có thể nhập dữ liệu đào tạo vào giao diện luồng theo video dưới đây.
Phân tích dữ liệu
Bước tiếp theo là phân tích dữ liệu đã nhập. Người dùng có thể chọn loại trình phân tích cú pháp, nhưng hầu hết, H2O sẽ tự động tìm ra nó. Trong trang Setup (Cài đặt) phân tích, người dùnng có thể chọn tên cột cũng như các loại cột. Đối với cột Churn, người dùng cần thay đổi kiểu dữ liệu từ số sang enum, viết tắt của một biến phân loại. Cột Churn là cột phản hồi, do đó, trong quá trình xây dựng mô hình, cột này sẽ tự động được mở rộng thành các biến giả.
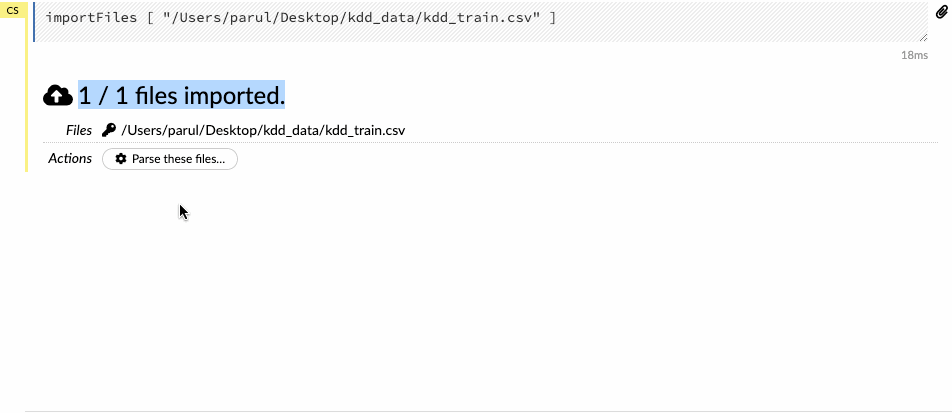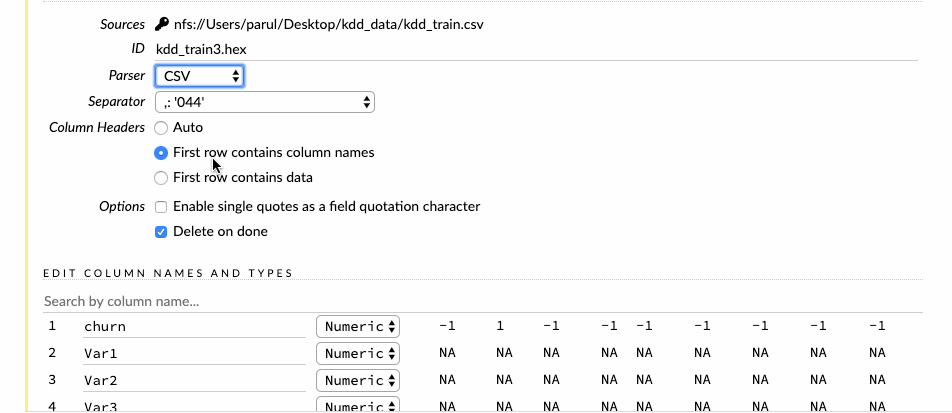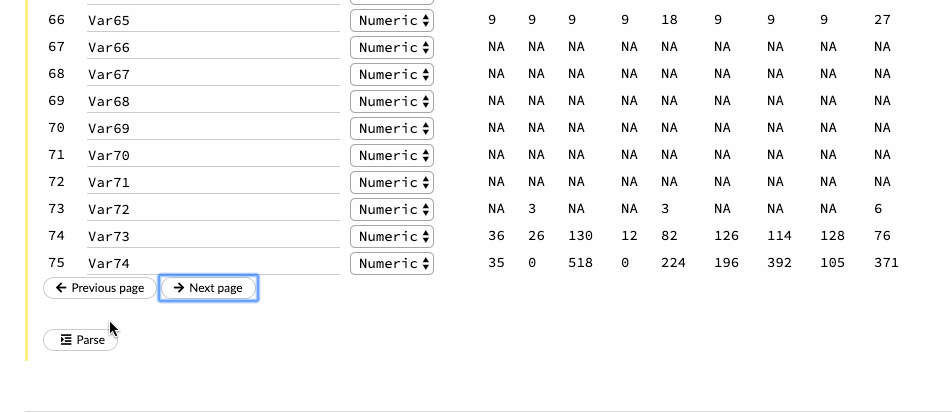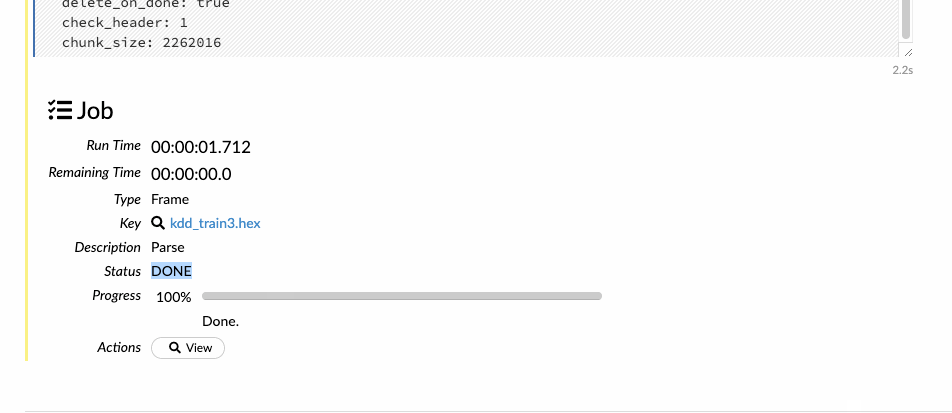
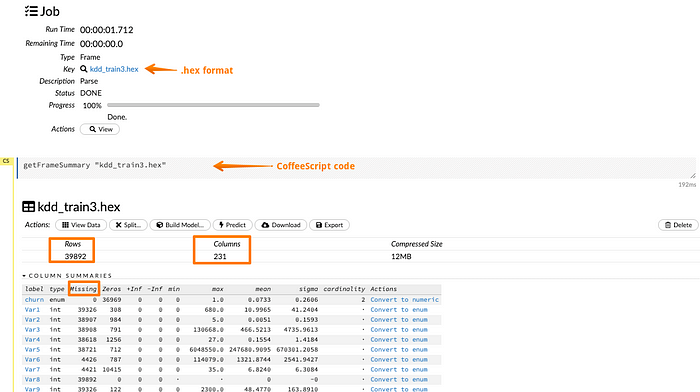
Tiếp theo, khi nhấn nút parse (phân tích), dữ liệu được phân tích và chuyển đổi sang định dạng .hex.
Người dùng cũng có thể hình dung từng nhãn dữ liệu bằng cách nhấp vào cột tương ứng. Người dùng có thể trực quan hóa cột churn và các phân phối khác nhau của nó.
Xây dựng mô hình
Trước khi tiến hành quá trình xây dựng mô hình, hai điều cần thiết phải được thực hiện:
Nhập dữ liệu còn thiếu
Nhấp vào tùy chọn Impute trong tab Data (Dữ liệu) và chọn một tiêu chí để loại bỏ trên các cột đã chọn của bộ dữ liệu.
Chia dữ liệu thành tập đào tạo và kiểm tra.
Việc phân tách dữ liệu đạt được bằng cách chỉ định tỷ lệ phân chia và theo đó, một khung đào tạo và thử nghiệm được tạo ra. Nhấp vào menu thả xuống Dữ liệu và chọn Split Frame (Chia Khung).
Xây dựng mô hình GBM
Khi đã hoàn thành việc khám phá dữ liệu, bạn có thể bắt đầu xây dựng một mô hình dự đoán sẽ được đưa vào sản xuất. Nhấp vào tab Model và Flow hiển thị danh sách tất cả các thuật toán có sẵn. H2O hỗ trợ nhiều loại thuật toán khác nhau từ GLM, GBM, AutoML cho đến DeepLearning. Danh sách đầy đủ được hiển thị dưới hình sau.
Với bài viết này, các chuyên gia sẽ xây dựng General Boosting machine -GBM, đây là một phương pháp học tập chuyển tiếp. Chọn các bộ dữ liệu và cột phản hồi và để tất cả các tùy chọn khác làm mặc định và sau đó xây dựng mô hình.
Xem xét mô hình
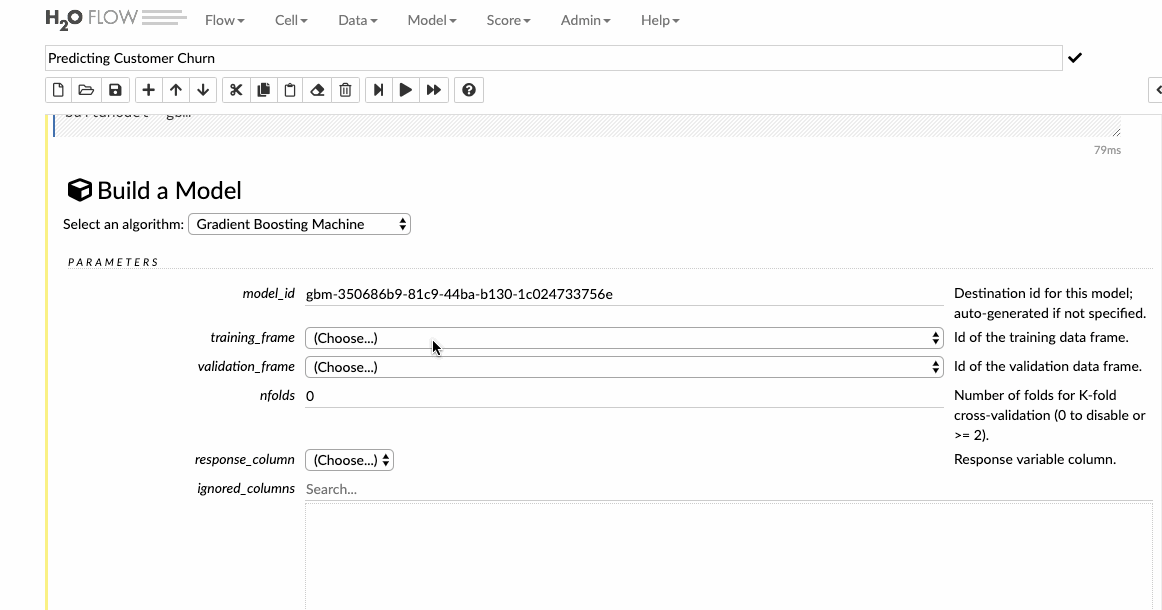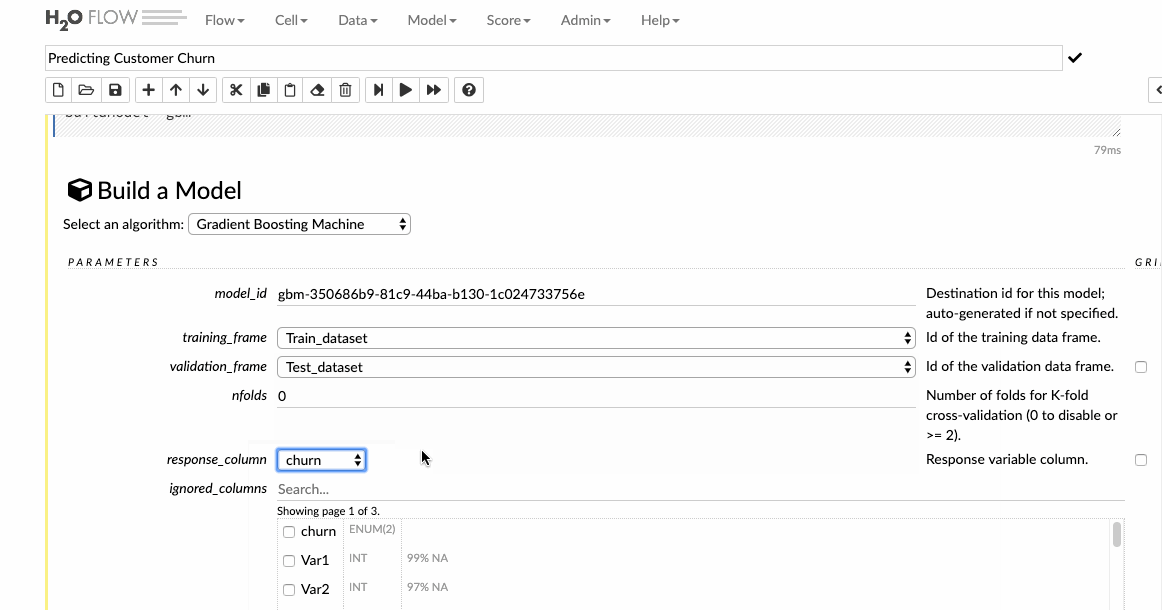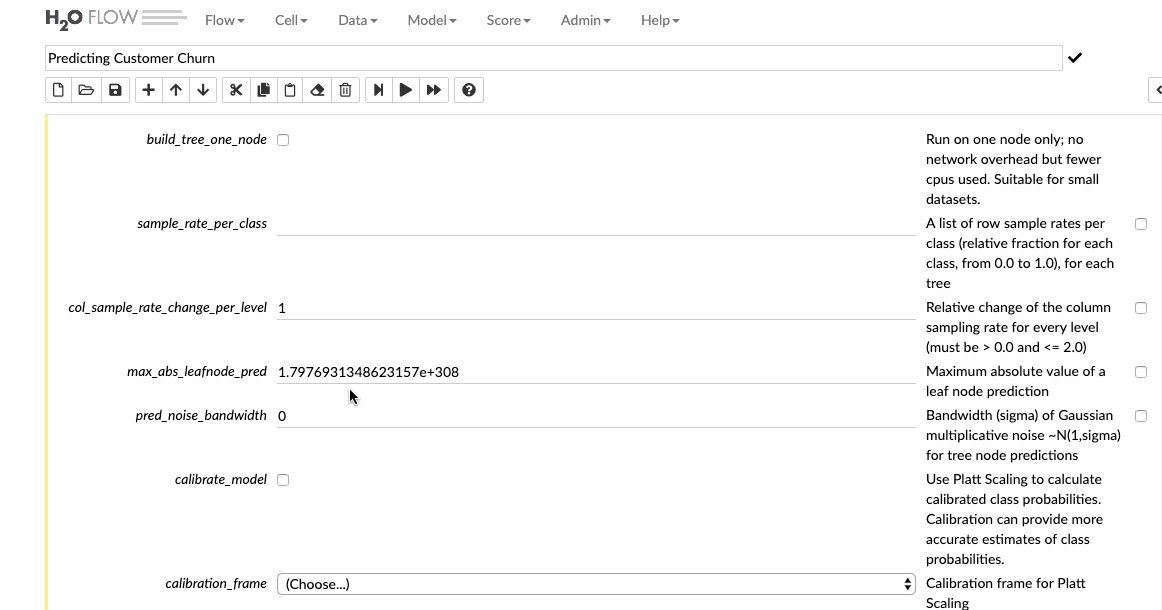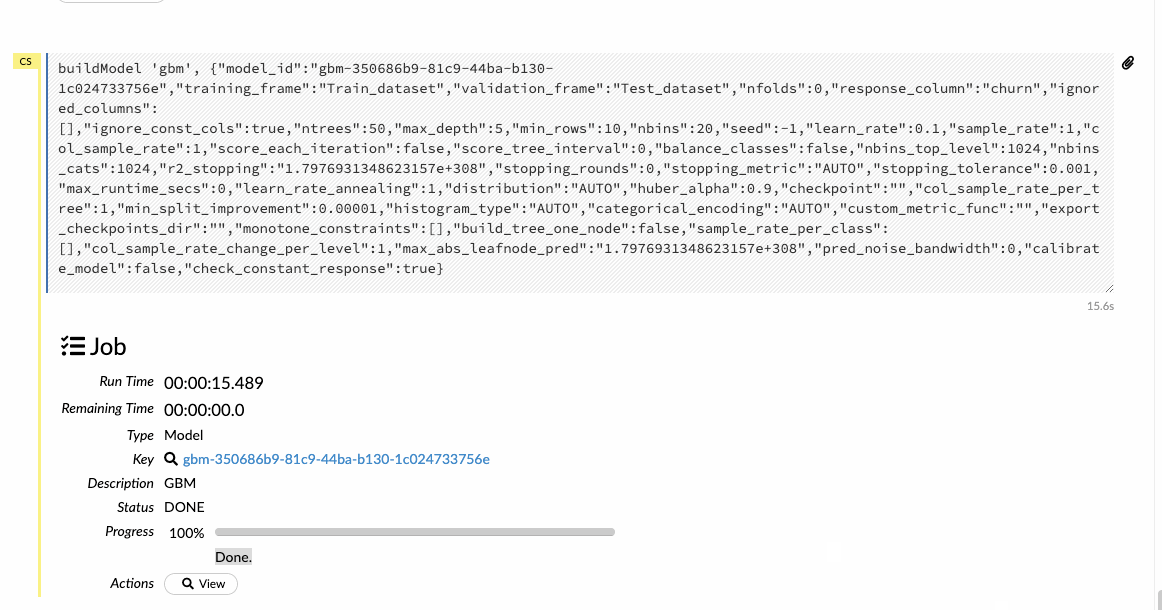
Dự đoán về dữ liệu xác nhận
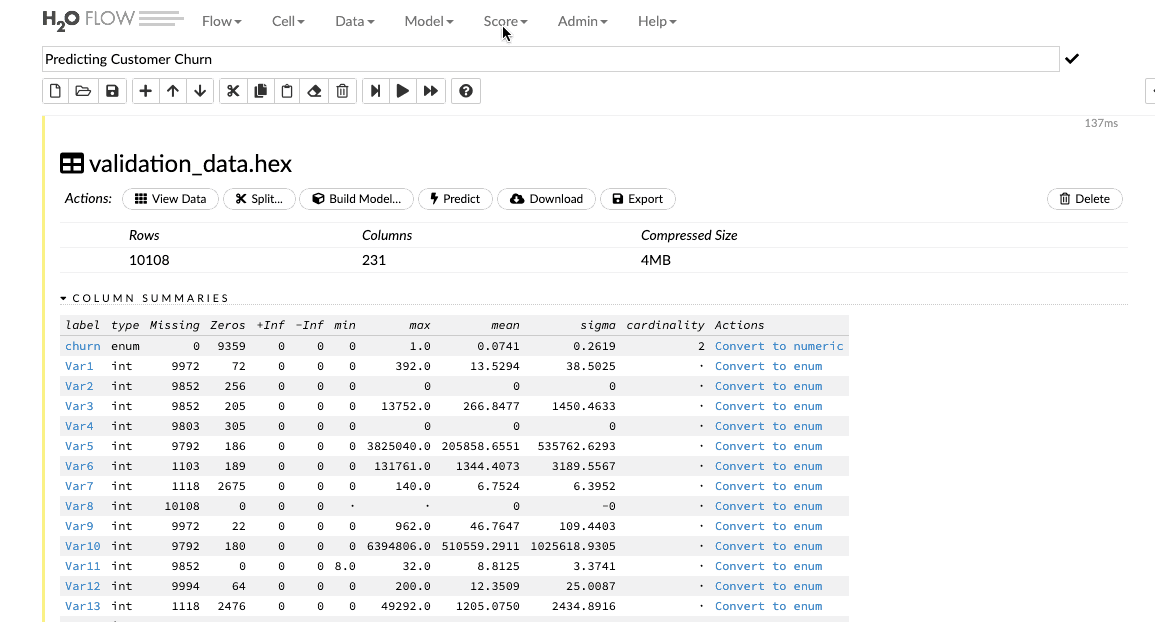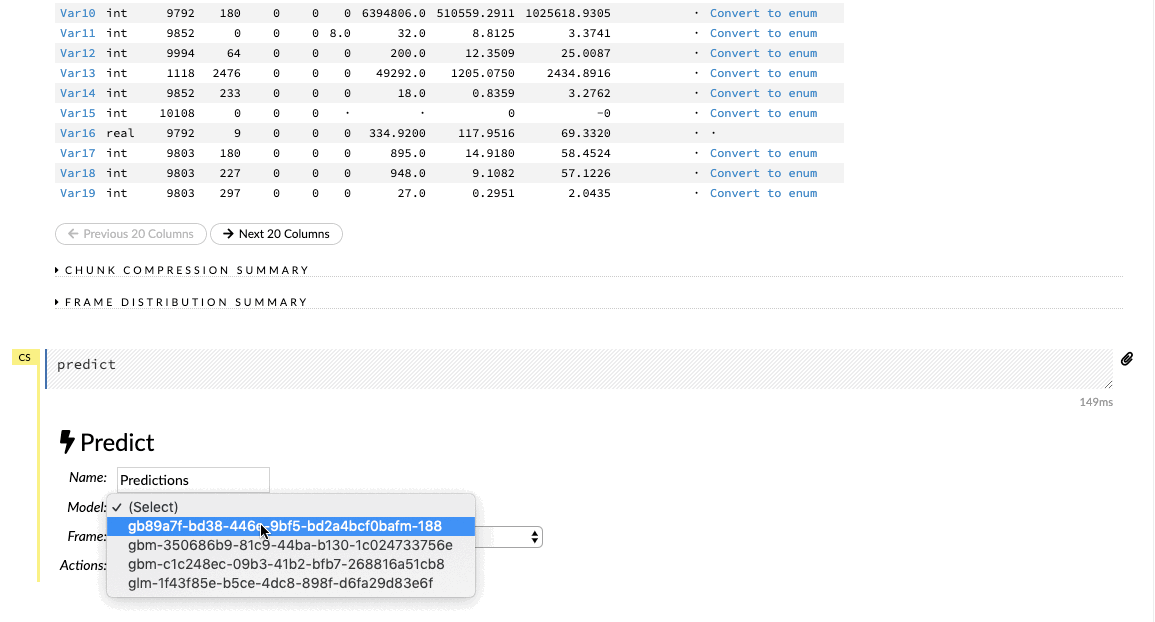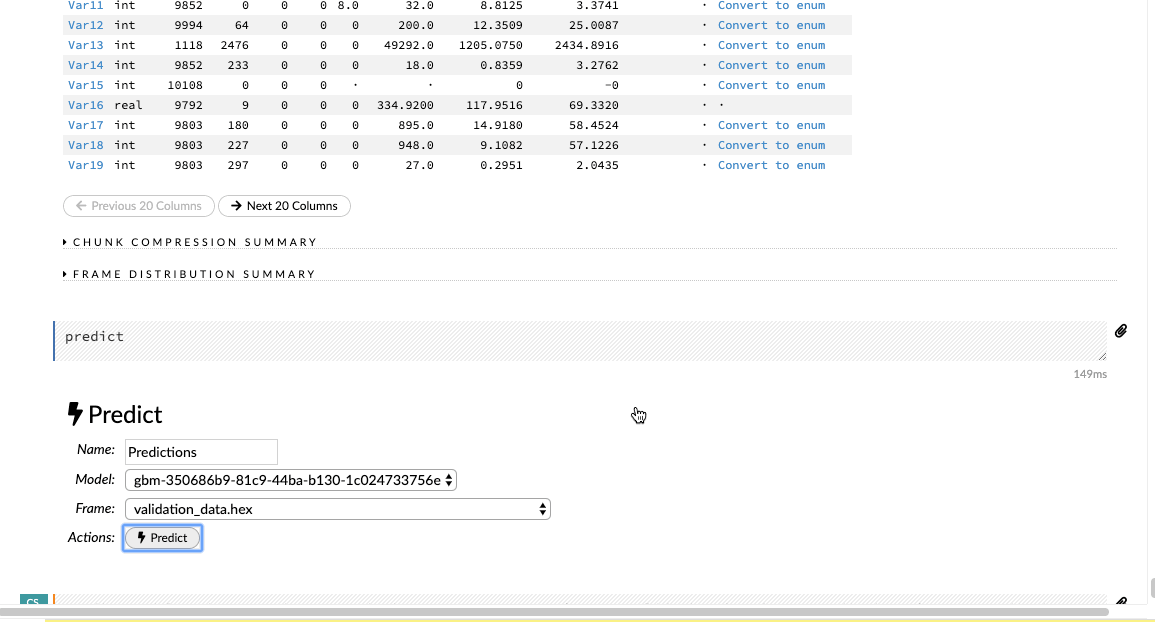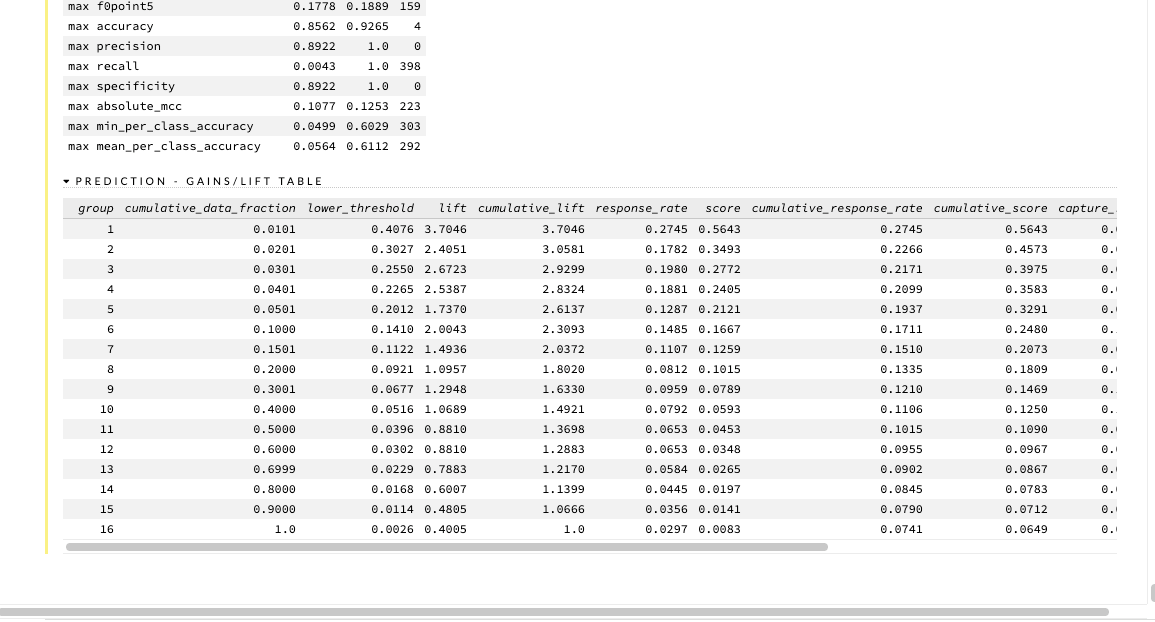
Sau khi đã xây dựng và điều chỉnh tham số của mô hình của mình để có được một số liệu hợp lý, người dùng có thể đưa ra dự đoán cho bộ dữ liệu xác thực của mình. Nhập tập dữ liệu xác thực vào giao diện luồng và nhấp vào tab Score (Điểm) > Predict (Dự đoán) để đưa ra các dự đoán cần thiết.
Mô hình sản xuất
Mục đích cuối cùng của một nhà khoa học dữ liệu không chỉ là xây dựng một mô hình mạnh mẽ, mà còn là một mô hình có thể được đưa vào sản xuất một cách dễ dàng. H2O cho phép người dùng chuyển đổi các mô hình mà họ đã xây dựng thành Plain Old Java Object (POJO) hoặc Model ObJect, Optimized (MOJO). Các mô hình MOJO và POJO do H2O tạo ra được dự định có thể dễ dàng tích hợp trong mọi môi trường Java. Vì vậy, nếu có một ứng dụng nội bộ để theo dõi khách hàng, người dùng có thể dễ dàng và nhanh chóng xuất một mô hình Plain Old Java Object (POJO) và tiếp tục chuyển nó cho các nhà phát triển để tích hợp nó vào các ứng dụng hiện có của họ. Theo cách này, mô hình dự đoán của người dùng có thể trở thành một phần của quy trình kinh doanh của họ.

Kết luận
Sự độc đáo của Flow nằm ở chỗ người dùng có thể chỉ và nhấp qua toàn bộ quy trình làm việc. Tuy nhiên, cơ chế điểm và nhấp này cũng tạo ra một CoffeeScript có thể được chỉnh sửa và sửa đổi, và có thể được lưu dưới dạng sổ ghi chép để có thể chia sẻ. Do đó, sau tất cả, người dùng không nhấp và chạy một cách không có chủ đích, mà người dùng nhận thức được mã đằng sau mỗi ô lệnh được thực hiện.















