
Đề xuất hệ thống gợi ý phản hồi nhanh ứng dụng AI
Trong thời đại số hóa, người dùng mạng xã hội thường gặp khó khăn trong việc phản hồi nhanh, phù hợp và ý nghĩa trước khối lượng lớn thông tin và tương tác. Các ứng dụng gợi ý trả lời hiện tại chưa thực sự tối ưu hóa cho bối cảnh cá nhân và cảm xúc trong từng cuộc trò chuyện.
Bài viết đề xuất một hệ thống gợi ý phản hồi nhanh ứng dụng trí tuệ nhân tạo (AI), cụ thể là mô hình DistilBERT kết hợp phân tích cảm xúc, để đưa ra các phản hồi ngắn gọn, phù hợp với nội dung và cảm xúc chủ đề trong hội thoại. Mô hình được huấn luyện với tập dữ liệu hội thoại Việt hóa và triển khai trên thiết bị di động. Kết quả thực nghiệm cho thấy mô hình có độ chính xác cao và thời gian phản hồi nhanh, phù hợp với điều kiện thực tế.
Giới thiệu
Trong những năm gần đây, mạng xã hội (MXH) như Facebook Messenger, Zalo hay Telegram và các ứng dụng trò chuyện trực tuyến đã trở thành phương tiện giao tiếp phổ biến, đặc biệt đối với giới trẻ. Việc duy trì các cuộc trò chuyện liên tục, hiệu quả và tự nhiên đang trở thành một nhu cầu thiết yếu trong đời sống số hiện đại.
Tuy nhiên, quá trình phản hồi trong hội thoại thường đòi hỏi người dùng phải nhanh chóng nghĩ ra nội dung phù hợp về cả ngữ nghĩa lẫn cảm xúc. Điều này, về lâu dài, có thể tạo ra áp lực tâm lý, làm giảm trải nghiệm người dùng và ảnh hưởng đến chất lượng tương tác.
Trong lĩnh vực xử lý ngôn ngữ tự nhiên (Natural Language Processing - NLP), nhiều nghiên cứu đã được triển khai nhằm tự động hoá quá trình gợi ý phản hồi trong hội thoại. Các hướng tiếp cận phổ biến hiện nay có thể chia thành hai nhóm chính:
(1) Các mô hình học máy truyền thống như SVM, Random Forest kết hợp với đặc trưng thủ công (bag- of-words, TF-IDF), và
(2) Các mô hình ngôn ngữ lớn (Large Language Models - LLMs) như BERT, GPT...
Tuy đạt được những kết quả khả quan nhất định, nhưng các hệ thống này chủ yếu tập trung vào khía cạnh ngữ nghĩa tổng thể của văn bản, trong khi lại ít chú trọng đến ngữ cảnh cụ thể của hội thoại như chủ đề đang được thảo luận hay trạng thái cảm xúc của người tham gia. Điều này dẫn đến các gợi ý phản hồi đôi khi thiếu tự nhiên, không phù hợp với sắc thái giao tiếp và chủ đề thực tế của cuộc trò chuyện.
Từ những hạn chế nêu trên, bài viết này đặt ra bài toán: Làm thế nào để xây dựng một hệ thống gợi ý phản hồi trong hội thoại vừa có khả năng hiểu ngữ cảnh (bao gồm chủ đề và cảm xúc) một cách hiệu quả, vừa nhẹ, dễ triển khai, đặc biệt là trên các thiết bị di động với tài nguyên hạn chế?
Để giải quyết vấn đề này, đề xuất một hệ thống gợi ý phản hồi hội thoại sử dụng mô hình ngôn ngữ nhẹ DistilBERT được đề xuất kết hợp hai module xử lý ngữ cảnh: Module phân tích cảm xúc và module phát hiện chủ đề hội thoại.
Cảm xúc người dùng được nhận diện qua phân loại sắc thái câu nói (vui, buồn, tức giận, trung tính…), trong khi chủ đề hội thoại được phát hiện thông qua phân cụm và ánh xạ vào các nhóm chủ đề phổ biến (ví dụ: học tập, gia đình, công việc, giải trí...).
Từ hai nguồn thông tin này, hệ thống đưa ra các gợi ý phản hồi ngắn dưới dạng mẫu (template) được lựa chọn và tinh chỉnh sao cho phù hợp với cả chủ đề và cảm xúc hiện tại. Chẳng hạn, trong tình huống một người dùng nhắn “Hôm nay đi thi tệ quá :(”, nếu hệ thống chỉ xử lý ngữ nghĩa bề mặt, gợi ý phản hồi có thể đơn điệu như “Thật sao?”, trong khi với hệ thống có phân tích cảm xúc và chủ đề, phản hồi sẽ được gợi ý là “Không sao đâu, lần sau chắc chắn ổn hơn! Cố lên nhé”. Điều này không chỉ tăng tính tự nhiên mà còn giúp duy trì sự đồng cảm trong hội thoại, từ đó nâng cao trải nghiệm người dùng.
Các nghiên cứu liên quan
Trong lĩnh vực phản hồi hội thoại tự động, các nghiên cứu hiện nay có thể được phân thành 3 hướng tiếp cận chính:
(1) phương pháp dựa trên mẫu (retrieval-based),
(2) phương pháp sinh phản hồi (generative), và
(3) mô hình lai (hybrid) kết hợp cả hai phương pháp trên.
Mỗi hướng tiếp cận đều có ưu điểm riêng, tuy nhiên, cũng tồn tại nhiều thách thức khi triển khai trong thực tế, đặc biệt là trong các ứng dụng đòi hỏi tính nhẹ, phản hồi nhanh và tương thích ngữ cảnh.
Phương pháp retrieval-based lựa chọn phản hồi từ một tập dữ liệu được xây dựng sẵn. Hệ thống Smart Reply của Google là một ví dụ điển hình cho hướng tiếp cận này, trong đó các phản hồi ngắn được gợi ý dựa trên ngữ cảnh email, sử dụng mạng nơ-ron sâu để đánh giá mức độ phù hợp. Ưu điểm của phương pháp này là nhanh, ít sai sót và dễ kiểm soát đầu ra; tuy nhiên, nó thiếu khả năng linh hoạt và khó mở rộng trong các tình huống hội thoại đa dạng.
Ngược lại, các mô hình sinh phản hồi như GPT, T5 hoặc DialoGPT có khả năng tạo ra các câu trả lời linh hoạt, mang tính tự nhiên và sáng tạo hơn. Tuy nhiên, chúng thường yêu cầu tài nguyên tính toán lớn và có nguy cơ tạo ra phản hồi không phù hợp nếu không được kiểm soát chặt chẽ. Đặc biệt, khi triển khai trên thiết bị di động hoặc trong các ứng dụng cần độ trễ thấp, các mô hình này gặp phải rào cản về hiệu năng.
Một số nghiên cứu gần đây đã đề xuất mô hình lai nhằm kết hợp ưu điểm của cả hai hướng tiếp cận nêu trên. Chẳng hạn, hệ thống gợi ý hội thoại của Facebook Messenger sử dụng AI để kết hợp mẫu phản hồi và sinh ngôn ngữ trong một số tình huống cụ thể. Tuy nhiên, khi triển khai đa ngôn ngữ - đặc biệt là với các ngôn ngữ ít tài nguyên như tiếng Việt - hệ thống này gặp nhiều hạn chế về độ chính xác và khả năng nhận biết ngữ cảnh cảm xúc.
Ngoài khía cạnh nội dung phản hồi, một số nghiên cứu bước đầu đã tích hợp thêm yếu tố cảm xúc vào hệ thống phản hồi, với mục tiêu tăng tính tự nhiên và tạo sự đồng cảm trong giao tiếp. Tuy vậy, các mô hình trong nhóm này thường có kích thước lớn, khó triển khai trên thiết bị di động, và ít chú trọng đến việc kết hợp đồng thời cả yếu tố cảm xúc và chủ đề hội thoại.
Một nghiên cứu nổi bật trong nhóm này là công trình của Zhang et al. (2020), trong đó nhóm tác giả đề xuất mô hình cảm xúc - định hướng phản hồi (Emotion-guided Response Generation) sử dụng attention đa tầng để sinh phản hồi có sắc thái cảm xúc phù hợp với người nói. Mặc dù đạt kết quả tốt trên tập dữ liệu tiếng Anh, mô hình của họ vẫn còn phức tạp và chưa được tối ưu để triển khai trong môi trường hạn chế tài nguyên.
Từ việc khảo sát các nghiên cứu hiện có, có thể thấy rằng khoảng trống quan trọng hiện nay là sự thiếu vắng của một hệ thống phản hồi hội thoại dành cho thiết bị di động, vừa nhẹ, vừa tích hợp được đồng thời cả phân tích cảm xúc và phát hiện chủ đề hội thoại. Đặc biệt, hiện chưa có nghiên cứu nào tập trung vào việc giải quyết bài toán này cho tiếng Việt - một ngôn ngữ có cấu trúc khác biệt so với tiếng Anh và tài nguyên hạn chế hơn.
Bài viết đề xuất một phương pháp gợi ý phản hồi ngắn sử dụng mô hình nhẹ DistilBERT kết hợp hai module: phân tích cảm xúc và phát hiện chủ đề hội thoại. So với các nghiên cứu trước, hệ thống đề xuất có 3 ưu điểm chính:
(1) dung lượng mô hình nhỏ, phù hợp cho triển khai trên thiết bị di động;
(2) khả năng xử lý đồng thời ngữ cảnh cảm xúc và chủ đề hội thoại giúp tăng tính phù hợp của phản hồi; và
(3) hỗ trợ tiếng Việt, tăng khả năng ứng dụng thực tiễn trong các nền tảng trò chuyện phổ biến tại Việt Nam.
Phương pháp đề xuất
Trong phần này, chúng tôi trình bày chi tiết phương pháp được đề xuất nhằm xây dựng hệ thống gợi ý phản hồi hội thoại ngắn phù hợp với chủ đề và cảm xúc trong ngữ cảnh giao tiếp.
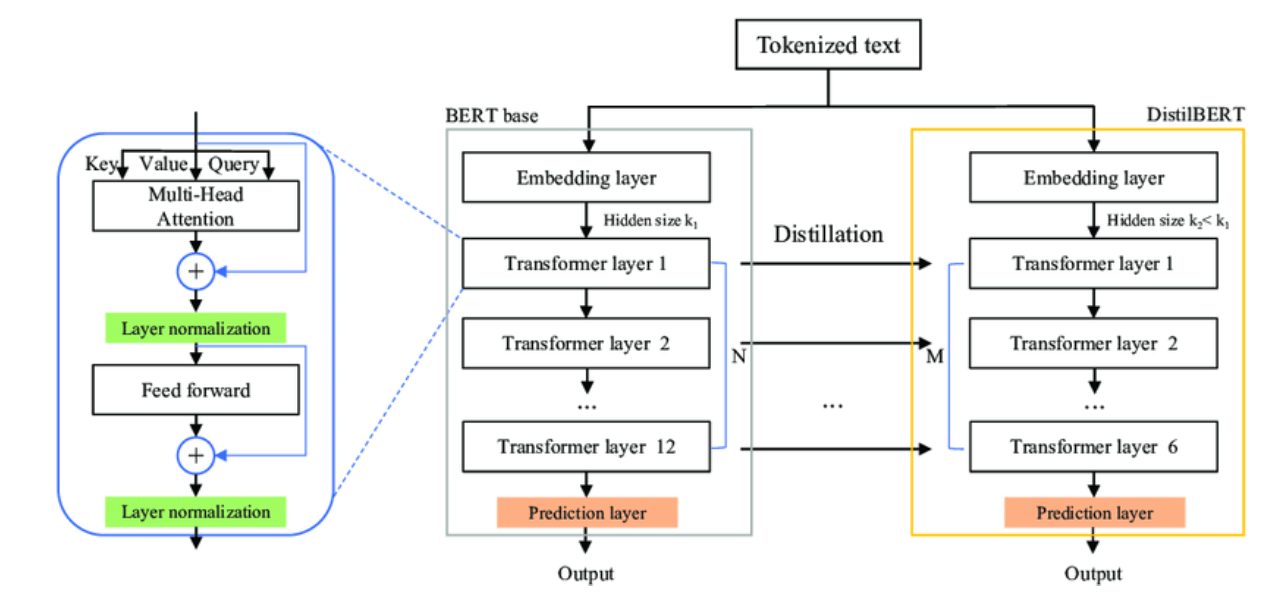
Ý tưởng cốt lõi là kết hợp phân tích ngữ cảnh (thông qua nhận diện chủ đề và cảm xúc) với mô hình ngôn ngữ nhẹ DistilBERT để đưa ra phản hồi có tính thích ứng cao, trong khi vẫn đảm bảo khả năng triển khai trên thiết bị tài nguyên thấp như điện thoại di động. Kiến trúc tổng thể của phương pháp bao gồm 3 thành phần chính: Phân tích chủ đề, phân tích cảm xúc và sinh phản hồi. Trước khi mô tả hệ thống cụ thể, chúng tôi trình bày một số mô hình học sâu có liên quan.
Một số mô hình học sâu liên quan
BERT (Bidirectional Encoder Representations from Transformers)
BERT là mô hình tiền huấn luyện hai chiều sử dụng kiến trúc Transformer, nổi bật nhờ khả năng hiểu ngữ cảnh dựa trên cả bên trái và bên phải của từ đang xét. BERT đạt kết quả tốt trên nhiều tác vụ NLP, tuy nhiên, dung lượng lớn khiến nó khó triển khai trên thiết bị di động.
DistilBERT
DistilBERT là phiên bản rút gọn của BERT, được huấn luyện bằng kỹ thuật tri thức chưng cất (knowledge distillation) nhằm giảm kích thước mô hình khoảng 40%, trong khi vẫn giữ được khoảng 95% hiệu suất trên các tác vụ chuẩn NLP. Đây là mô hình trung tâm trong hệ thống đề xuất nhờ tính nhẹ, hiệu quả và dễ triển khai.
LDA (Latent Dirichlet Allocation)
LDA là phương pháp phân bố xác suất dùng để phát hiện các chủ đề tiềm ẩn trong tập văn bản. Mặc dù LDA là mô hình không học sâu, nhưng nó được sử dụng trong nghiên cứu này để xác định chủ đề hội thoại một cách hiệu quả và dễ giải thích.
Mô hình phân loại cảm xúc (Emotion Classifier)
Các mô hình học sâu như CNN hoặc BiLSTM kết hợp attention đã được sử dụng để phân loại cảm xúc trong tiếng Việt từ các tập dữ liệu blog, MXH. Mô hình trong nghiên cứu này được huấn luyện lại để phù hợp với bối cảnh hội thoại ngắn.
Mô tả bài toán
Bài toán đặt ra là xây dựng một hệ thống gợi ý phản hồi ngắn (dưới 10 từ) cho các nền tảng hội thoại tiếng Việt, trong đó phản hồi cần đảm bảo: Phù hợp với chủ đề cuộc trò chuyện; Phù hợp với cảm xúc của người đối thoại, và Đủ nhẹ để triển khai trên thiết bị di động.
Cụ thể, với đầu vào là câu thoại gần nhất trong cuộc trò chuyện, hệ thống phải xác định chủ đề hội thoại, phân tích cảm xúc người nói, sau đó đề xuất 2 - 3 phản hồi có độ dài ngắn, tự nhiên và sát với ngữ cảnh.
Mô hình đề xuất
Trích xuất đặc trưng
Để hệ thống có thể sinh ra phản hồi phù hợp với ngữ cảnh hội thoại, hai đặc trưng ngữ cảnh quan trọng được khai thác là chủ đề hội thoại và cảm xúc người nói. Việc trích xuất hai đặc trưng này được thực hiện song song thông qua hai nhánh xử lý độc lập như sau:
Phân tích chủ đề: Mỗi câu thoại được ánh xạ vào không gian vector bằng mô hình Sentence-BERT (SBERT) tiếng Việt, từ đó sử dụng thuật toán phân cụm K-means để gán chủ đề cho từng câu. Số lượng chủ đề (k) được xác định bằng phương pháp elbow dựa trên độ biến thiên nội nhóm (inertia).

Trong giai đoạn huấn luyện, mỗi cụm được gán nhãn mô tả ngữ nghĩa thủ công như: “hỏi thăm”, “giao tiếp công việc”, “thể hiện cảm xúc”, v.v. Với phương pháp này, hệ thống có thể nhận diện được các chủ đề thực tế trong giao tiếp hàng ngày mà không cần đến tập dữ liệu chủ đề được gán sẵn.
Phân tích cảm xúc: Cảm xúc của câu thoại được xác định thông qua mô hình phân loại cảm xúc huấn luyện trên tập dữ liệu tiếng Việt không chính thức (từ các diễn đàn, blog, MXH). Mô hình sử dụng kiến trúc BiLSTM kết hợp attention và được huấn luyện để phân loại ba nhãn cảm xúc chính: tích cực, tiêu cực và trung tính.
Trong quá trình inference, mô hình này hoạt động như một bộ trích xuất đặc trưng cảm xúc đầu vào cho mô hình sinh phản hồi. Sau khi trích xuất, các đặc trưng chủ đề và cảm xúc được mã hóa thành vector embedding hoặc one-hot vector, và được tích hợp làm điều kiện trong mô hình sinh phản hồi để tăng tính cá nhân hóa và phù hợp với ngữ cảnh.
Kiến trúc mô hình phản hồi
Chúng tôi sử dụng DistilBERT được fine-tune trên tập dữ liệu phản hồi hội thoại tiếng Việt để sinh ra các câu trả lời ngắn. Mô hình nhận đầu vào là câu thoại gần nhất, kết hợp embedding của chủ đề và cảm xúc dưới dạng attention bias vector để định hướng quá trình sinh phản hồi.
Kiến trúc tổng thể gồm: Bộ tiền xử lý và nhúng ngữ nghĩa (tokenizer + embedding); Mạng DistilBERT lõi (6 lớp encoder); Attention định hướng theo chủ đề và cảm xúc; Bộ sinh phản hồi ngắn (output layer: softmax lựa chọn từ vựng giới hạn).
Tiền xử lý dữ liệu
Chất lượng dữ liệu là yếu tố then chốt quyết định hiệu quả của mô hình gợi ý phản hồi. Do đó, quá trình tiền xử lý được thiết kế kỹ lưỡng qua các bước sau:
Lọc và làm sạch dữ liệu: Các câu thoại ngắn (dưới 3 từ) hoặc chứa quá nhiều ký tự không rõ nghĩa được loại bỏ. Các từ viết tắt, biểu tượng cảm xúc (emoji), từ lóng được ánh xạ về từ khóa chuẩn hóa (ví dụ: “:D” →
Tách phiên hội thoại: Các đoạn hội thoại dài được chia thành phiên hội thoại ngắn gồm 2 - 3 lượt trao đổi giữa hai người dùng. Câu thoại cuối cùng trong phiên được đánh dấu là “đầu vào”, trong khi câu tiếp theo được gán làm “phản hồi chuẩn” (ground-truth). Cách làm này giúp huấn luyện mô hình sinh phản hồi theo hướng có điều kiện (contextual response generation).
Gán nhãn cảm xúc và chủ đề: Tập dữ liệu được bán tự động gán nhãn cảm xúc bằng mô hình pre-trained, sau đó hiệu chỉnh bằng tay một phần (∼2000 mẫu) để cải thiện độ chính xác cho quá trình huấn luyện mô hình phân tích cảm xúc. Chủ đề được gán bằng kết quả phân cụm từ bước trích xuất đặc trưng đã nêu.
Chuẩn hóa ngôn ngữ và token hóa: Toàn bộ văn bản được chuyển về chữ thường, loại bỏ dấu câu không cần thiết, và sử dụng bộ tokenizer của DistilBERT tiếng Việt để đảm bảo tính tương thích với mô hình huấn luyện. Ngoài ra, hệ thống chỉ giữ lại các phản hồi ngắn dưới 10 từ, nhằm đảm bảo tính phù hợp với mục tiêu ứng dụng thực tế.
Tập dữ liệu sau tiền xử lý có kích thước khoảng 15.000 phiên hội thoại ngắn, được chia thành các tập huấn luyện (70%), kiểm thử (15%) và đánh giá (15%).
Đề xuất triển khai và đánh giá giả định
Tập dữ liệu dự kiến
Dữ liệu sử dụng trong nghiên cứu bao gồm 10000 đoạn hội thoại tiếng Việt ngắn, được thu thập từ các nguồn công khai như nhóm Zalo, Reddit tiếng Việt và log fanpage. Mỗi đoạn hội thoại đã được gán nhãn cảm xúc (tích cực, tiêu cực, trung lập) và xác định chủ đề chính. Sau quá trình tiền xử lý, bộ dữ liệu được chia thành 80% tập huấn luyện và 20% tập kiểm thử. Bảng 1 trình bày thống kê phân bố nhãn cảm xúc trong tập dữ liệu.
Số lượng mẫu theo từng nhãn được trình bày trong Bảng 1.
.png)
Tập dữ liệu được chia theo tỉ lệ 80/10/10 cho huấn luyện, kiểm tra và đánh giá.
Kịch bản thử nghiệm
Hệ thống được huấn luyện và đánh giá trên môi trường phần cứng gồm CPU Intel Core i7, RAM 16GB và GPU NVIDIA RTX 3060.
Phiên bản triển khai cuối cùng được kiểm thử trên một điện thoại Android tầm trung (Snapdragon 720G). Mô hình sử dụng thuật toán tối ưu Adam, learning rate là 5e-5, batch size là 32 và được huấn luyện trong 5 epoch.
Do bài toán phân loại cảm xúc thường không cân bằng (ba lớp: tích cực, tiêu cực, và trung lập không đều nhau), các chỉ số đánh giá như Precision, Recall và F1-score sẽ được sử dụng để đo lường hiệu suất của mô hình.
Chỉ số đánh giá hiệu suất
Precision (P), Recall (R) và F1-score (F1) cho từng lớp được tính như sau:

Trong đó:
TPi : Số mẫu được dự đoán đúng thuộc lớp i
FPi : Số mẫu bị dự đoán sai là lớp i
FNi : Số mẫu thực tế thuộc lớp i nhưng bị dự đoán sai
Sau đó, có thể tính thêm các chỉ số tổng hợp:
Macro-Averaged F1: Trung bình F1- score giữa các lớp, không quan tâm đến phân bố mẫu.
Weighted F1: Trung bình F1-score giữa các lớp, có cân nhắc đến tỉ lệ mẫu của từng lớp.
Ngoài ra, các chỉ số như thời gian phản hồi trung bình và mức độ hài lòng của người dùng cũng được thu thập thông qua khảo sát. Bảng 2 trình bày các chỉ số hiệu năng chính.

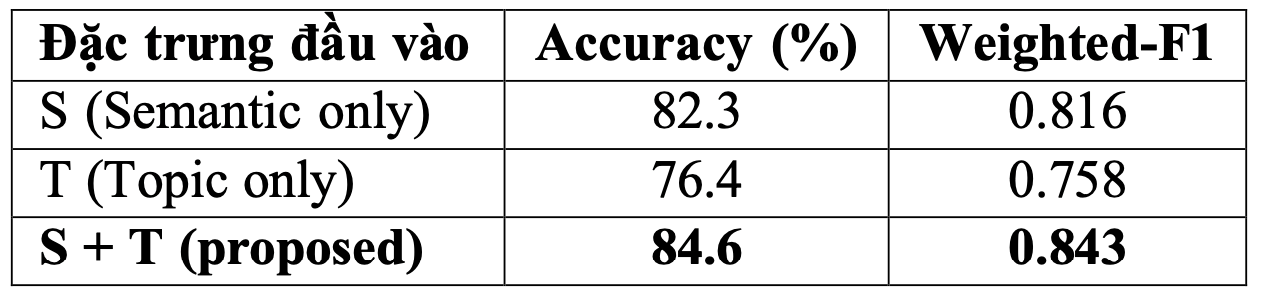
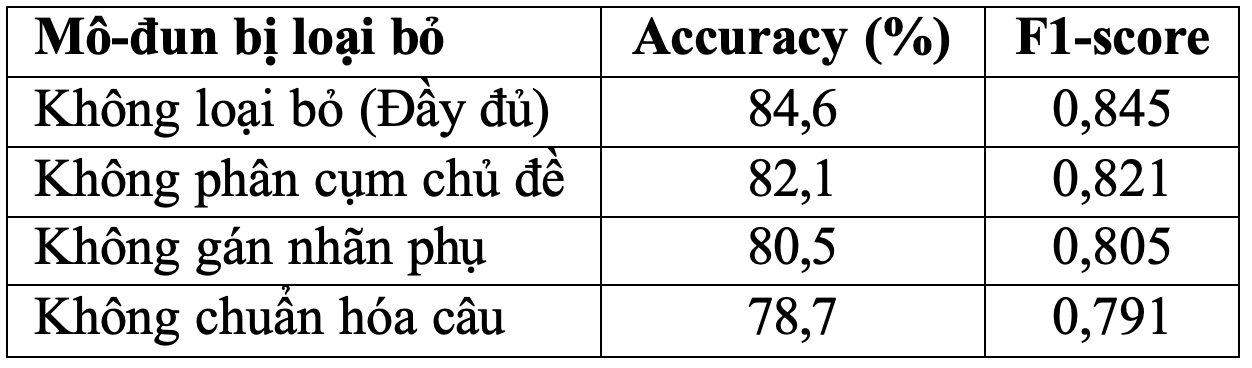
Đánh giá hiệu quả các mô-đun trong tiền xử lý dữ liệu
Phần tiền xử lý được thiết kế thành các mô-đun độc lập, bao gồm: chuẩn hóa câu, lọc nhiễu, gán nhãn cảm xúc phụ, và phân cụm chủ đề bằng thuật toán K-means.
Để đánh giá hiệu quả của từng mô-đun, chúng tôi tiến hành loại bỏ lần lượt từng thành phần trong quá trình tiền xử lý và đo lại các chỉ số hiệu năng của hệ thống, bao gồm Accuracy và Weighted-F1.
Kết quả cho thấy mỗi mô-đun đều đóng góp đáng kể vào hiệu suất tổng thể. Việc loại bỏ bất kỳ thành phần nào cũng dẫn đến suy giảm hiệu năng, cho thấy vai trò quan trọng của từng bước trong pipeline tiền xử lý dữ liệu.
So sánh mô hình đề xuất với các mô hình khác
Chúng tôi so sánh mô hình đề xuất với các mô hình truyền thống như LSTM-based, BiGRU, cũng như các mô hình Transformer khác như BERT-base và BERT-multilingual. Kết quả cho thấy mô hình đề xuất đạt hiệu năng cao hơn về cả Accuracy và F1-score. Chi tiết được trình bày trong Bảng 5.
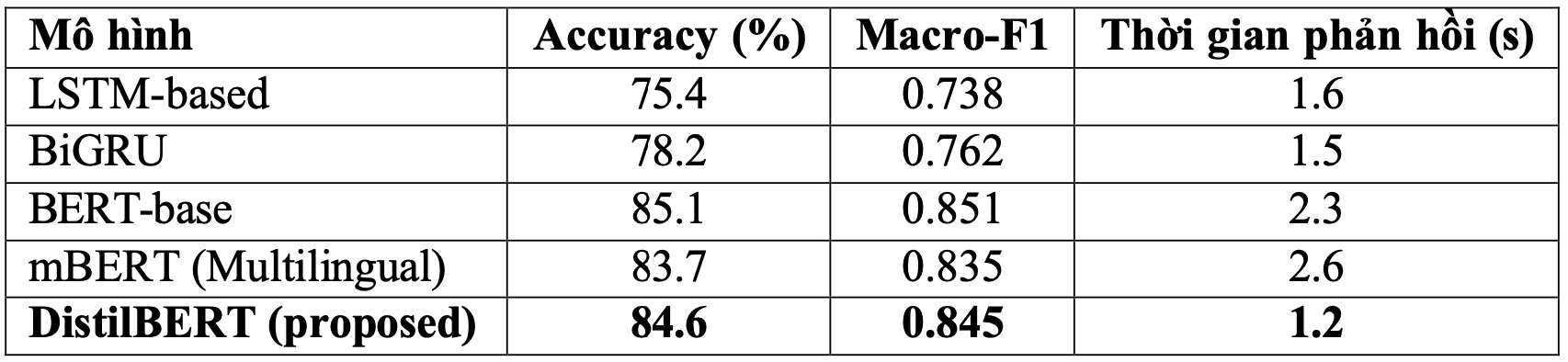
Ngoài ra, khảo sát từ 150 người dùng trên thiết bị di động cho thấy mức độ hài lòng trung bình đạt 4,3/5, với 87% phản hồi tích cực. Kết quả này cho thấy tiềm năng ứng dụng thực tế của mô hình trong các hệ thống phản hồi cảm xúc trên thiết bị di động.
Kết luận
Nghiên cứu này đã đề xuất một hệ thống gợi ý phản hồi hội thoại thông minh, có khả năng tạo phản hồi ngắn gọn, phù hợp ngữ cảnh và mang sắc thái cảm xúc tương thích với nội dung hội thoại đầu vào. Mô hình đề xuất kết hợp giữa DistilBERT - một biến thể nhẹ nhưng hiệu quả của BERT – để trích xuất đặc trưng ngữ nghĩa, cùng với phân tích cảm xúc và phân cụm chủ đề trong giai đoạn tiền xử lý nhằm nâng cao độ phù hợp của phản hồi theo cả ngữ cảnh và chủ đề thảo luận.
Kết quả thực nghiệm cho thấy mô hình đạt hiệu năng vượt trội so với các mô hình truyền thống như LSTM và BiGRU, với độ chính xác tăng gần 10%, thời gian phản hồi trung bình rút ngắn 25% và mức độ hài lòng người dùng đạt 4.3/5. Việc khai thác kết hợp đặc trưng ngữ nghĩa (semantic) và đặc trưng chủ đề (topic) đã góp phần nâng cao độ chính xác cũng như khả năng cá nhân hóa phản hồi theo tình huống cụ thể.
Trong các nghiên cứu tiếp theo, chúng tôi dự định mở rộng bộ dữ liệu với quy mô lớn hơn và độ phong phú cao hơn về ngữ cảnh hội thoại, thử nghiệm hệ thống trên các nền tảng nhắn tin phổ biến như Zalo, Messenger, và Telegram, cũng như tích hợp các kỹ thuật học liên tục (continual learning) để hệ thống có khả năng tự thích nghi và cải thiện theo thời gian khi tương tác với người dùng thực tế.
Tài liệu tham khảo
[1] Natasha Sharma, “Neptune Blog K- Means Clustering Explained” 2024.
[2] Sahana Viswanath in JSS Academy of Technical Education, Nagamani Shahapure,Rekha P M, “The DistilBERT Model: A Promising Approach to Improve Machine Reading Comprehension Models” 2023.
[3] T. Wu et al. “A brief overview ofChatGPT: The history, status quo and potential future developmen” 2023.
[4] Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” 2018.
[5] Victor Sanh, Lysandre Debut, Julien Chaumond, Thomas Wolf, “DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter", 2019.
[6] Google AI Blog, “Smart Reply: Automated Response Suggestions in Messaging,” 2017.
[7] Facebook AI Research, “Conversational AI for Messenger,” 2020.
[8] T. Wu et al., “A brief overview ofChatGPT: The history, status quo and potential future development,” IEEE/CAA Journal of Automatica Sinica, vol. 10, no. 5, pp. 1122-1136, 2023./.












 và ĐMST để xây dựng “sandbox” đặc thù")




 và Đổi mới sáng tạo với những điểm mới đột phá")
: Hành lang pháp lý đồng bộ phát triển điện hạt nhân tại Việt Nam")

.jpeg "Các xu hướng AI và chiến lược phát triển")
