
Chìa khoá để chăm sóc sức khoẻ thông minh và an toàn hơn
Y tế ngày càng thông minh nhờ áp dụng trí tuệ nhân tạo (AI), trong đó mô hình học máy (ML) “học” cách ra quyết định căn cứ trên bản mẫu thu thập được từ tập hợp quy mô lớn các dữ liệu của bệnh nhân.
Theo Alexis Crowell, Phó Chủ tịch phụ trách Kinh doanh, Tiếp thị và Truyền thông kiêm Giám đốc Điều hành Khu vực châu Á của Intel Corporation, điều đó giúp cải thiện độ chính xác trong chẩn đoán y khoa, đồng thời đẩy nhanh tốc độ nghiên cứu và phát triển nhiều phương thuốc cấp thiết.
Dù vậy, trong những năm gần đây, các chuyên gia phát hiện rằng quy trình phát triển ứng dụng ML truyền thống qua bộ dữ liệu tập trung hoá vẫn còn nhiều thiếu sót, bởi lẽ các mô hình ML cho chăm sóc sức khoẻ (CSSK) yêu cầu lượng dữ liệu nhiều hơn những gì có thể chia sẻ công khai, vốn bị giới hạn bởi vấn đề bảo mật và quyền riêng tư.
Những thách thức này đã và đang cản trở AI đưa ngành y tế lên một tầm cao mới, nơi các mô hình ML chỉ có thể đạt được độ chính xác cấp độ lâm sàng nếu được trích xuất từ các bộ dữ liệu đủ lớn, đủ đa dạng và được giám sát, biên tập kỹ lưỡng.
Nhằm dân chủ hoá AI và hưởng lợi từ dữ liệu trong CSSK, cần xây dựng một phương pháp huấn luyện các mô hình ML không bị ảnh hưởng từ nguy cơ trong việc chia sẻ dữ liệu nhạy cảm bên ngoài cơ sở lưu trữ. Học liên kết (federated learning) là chìa khoá mở ra phương pháp đó.
Học tập tập trung không còn mang tính bền vững trong y tế
Học tập tập trung vốn là quy chuẩn truyền thống lâu nay trong mô hình hoá AI. Phương thức này yêu cầu thu thập bộ dữ liệu từ nhiều thiết bị và địa điểm, sau đó chuyển dữ liệu đến một địa điểm tập trung để thực hiện huấn luyện mô hình ML.
Điều này phát sinh không ít nguy cơ. Đầu tiên, dữ liệu được lưu trữ tập trung có thể bị đánh cắp và phơi bày, khiến cơ sở lưu trữ chịu trách nhiệm pháp lý rất lớn. Nguy cơ kế tiếp là các chủ sở hữu dữ liệu thậm chí có thể không muốn chia sẻ dữ liệu thô. Cho dù chủ sở hữu dữ liệu nguyện ý hợp tác để huấn luyện ML, thì dữ liệu thô cũng quá nhạy cảm để có thể chia sẻ.
Các mối lo ngại về bảo mật và quyền riêng tư cũng khiến công tác triển khai ở quy mô toàn cầu gặp nhiều khó khăn, nhất là với những câu hỏi về quyền sở hữu dữ liệu, tài sản trí tuệ (IP), và tuân thủ nhiều quy định luật pháp đa dạng của các quốc gia sở tại.
Những hạn chế này khiến ngày càng ít cơ quan, tổ chức đóng góp vào công tác chia sẻ dữ liệu. Việc đó cản trở mô hình ML từ các nguồn dữ liệu đa dạng, phong phú từ các tổ chức hay địa phương khác nhau, và hậu quả tất yếu là sẽ tạo ra nhận thức thiên kiến và không chính xác.
Học liên kết mang đến những gì?
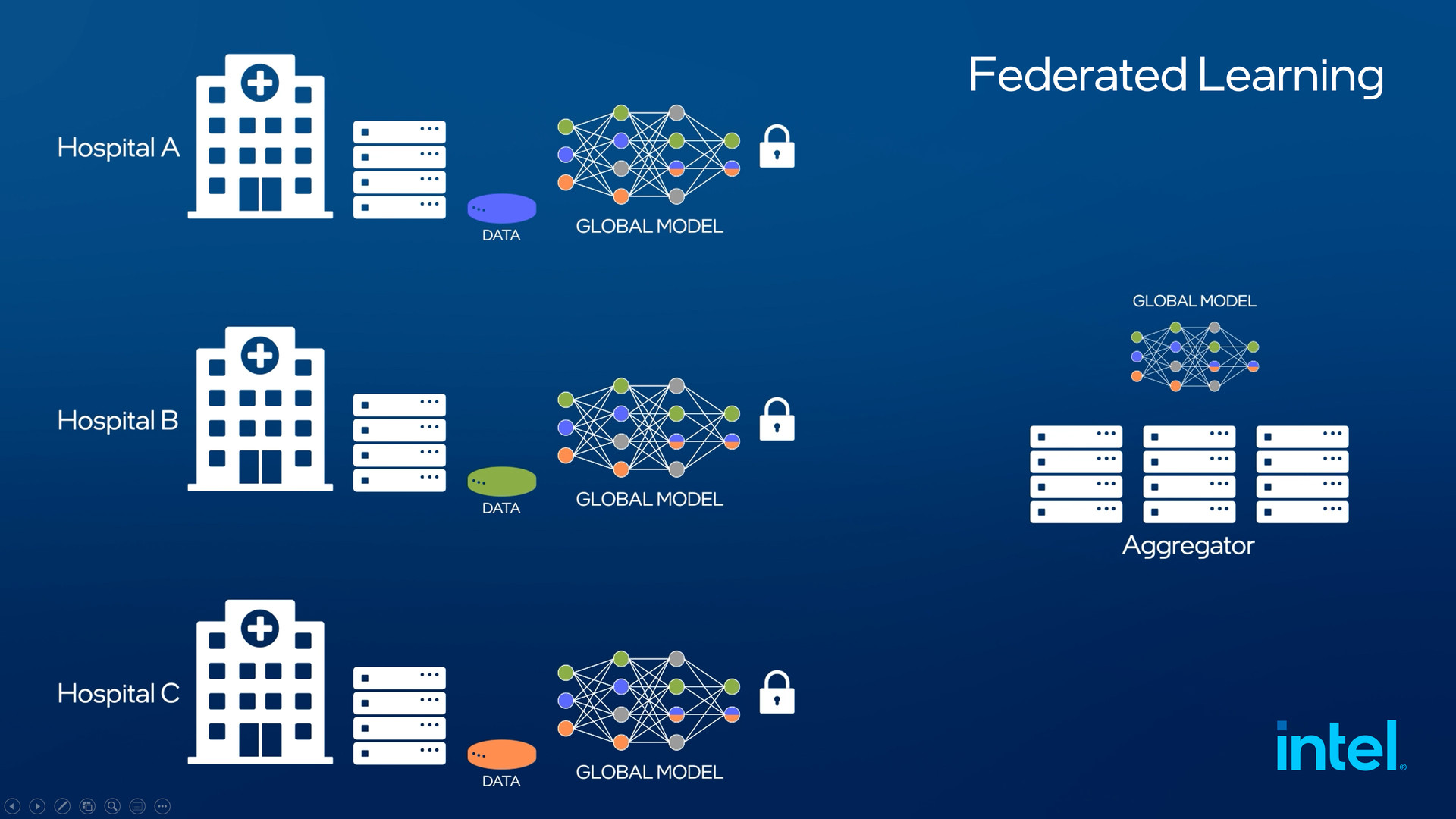
Ý tưởng chính làm nền tảng cho học liên kết là huấn luyện một mô hình ML dựa trên dữ liệu người dùng mà không cần phải truyền tải dữ liệu đó đến bất kỳ địa điểm nào khác. Cụ thể, thay vì chuyển dữ liệu đến nơi tập huấn, chúng ta sẽ đưa quy trình tính toán đến chính cơ sở hạ tầng của cơ quan, tổ chức sở hữu dữ liệu. Tại đó, một máy chủ trung tâm sẽ chịu trách nhiệm tập hợp những kết quả, nhận thức thu thập được từ công tác tính toán, tập huấn nhiều nguồn dữ liệu.
Học liên kết thực hiện nhiều chu trình huấn luyện trên chính các thiết bị, máy móc tại chỗ, đảm bảo rằng dữ liệu của Việt Nam luôn được lưu trữ trong nước. Lợi ích của việc này là sẽ không gây tổn hại hay bộc lộ dữ liệu đang di chuyển. Mặc dù dữ liệu vẫn được khai thác để kiến tạo nhận thức trên toàn cầu, nhưng lại luôn thuộc sự kiểm soát của người sở hữu. Những tham số mô hình thu hoạch được từ công tác huấn luyện tại chỗ chủ sở hữu dữ liệu sẽ được gửi đến một máy chủ trung tâm, và tập hợp lại để hình thành một mô hình toàn cầu mới, sau đó chia sẻ với tất cả các bên tham gia.
Hiện tại thì học liên kết đã gây tiếng vang bằng việc sử dụng AI tối tân để phát hiện các khối u não chính xác hơn. Từ năm 2020, Intel và Trường đại học Pennsylvania đã triển khai nghiên cứu học tập liên kết với quy mô lớn nhất ngành y tế. Sử dụng các bộ dữ liệu từ 71 cơ sở, học viện trên khắp 6 châu lục, nghiên cứu này cho thấy khả năng cải thiện phát hiện u não chính xác hơn 33%.
Để tạo dựng một nền tảng vững chắc cho học liên kết, phải bắt đầu bằng lòng tin
Đứng trước khối lượng dữ liệu khổng lồ hiện hành, điều tiên quyết là các cơ quan, tổ chức tại Việt Nam phải thiết lập được một chiến lược bảo mật dữ liệu chắc chắn và hiệu quả. Chìa khoá cho việc này chính là lưu trữ những dữ liệu nhạy cảm tại đám mây nằm trong một khu vực hạn chế truy cập, thường được gọi là Môi trường Thực thi Tin cậy (Trusted Execution Environment - TEE). Bảo vệ quyền riêng tư là công tác thiết yếu nhằm duy trì liên tục khả năng bảo vệ khối lượng công việc kèm theo quy định của cơ quan chức năng hoặc bảo vệ dữ liệu nhạy cảm trên các mạng lưới chia sẻ chung.
Trong bối cảnh điện toán ngày càng xâm nhập vào nhiều môi trường đa dạng - từ các hệ thống sở tại cho đến đám mây công cộng và vùng biên đám mây, các cơ quan, tổ chức cần thiết lập cơ chế kiểm soát bảo mật nhằm bảo vệ tài sản trí tuệ và thông tin công việc nhạy cảm ở bất cứ nơi nào hiện đang lưu trữ dữ liệu, cũng như đảm bảo công tác làm việc từ xa cũng được thực thi với đoạn mã lệnh đã định. Đây là lúc điện toán an toàn phát huy thế mạnh.
Khác với quy trình mã hoá dữ liệu truyền thống dành cho dữ liệu ở trạng thái nghỉ hay đang được truyền tải, điện toán an toàn tận dụng TEE để tăng cường độ bảo mật và quyền riêng tư của đoạn mã lệnh sẽ được thực thi và dữ liệu đang sử dụng.
Điện toán an toàn giúp các bộ dữ liệu được xử lý an toàn hơn, và giảm thiểu nguy cơ bị tấn công bằng cách cô lập mã lệnh và dữ liệu khỏi sự xâm nhập từ bên ngoài. Là công nghệ điện toán an toàn được nghiên cứu và triển khai nhiều nhất trong các trung tâm dữ liệu hiện nay, Intel Software Guard Extensions (Intel SGX) cung cấp giải pháp bảo mật dựa trên phần cứng giúp bảo vệ dữ liệu đang sử dụng bằng một công nghệ cô lập ứng dụng độc đáo.
Nhờ vào nền tảng bảo mật dựa trên phần cứng, các bề mặt tấn công nhiều lỗ hổng nay đã có thể được gia cố để không chỉ bảo vệ khỏi các cuộc tấn công phần cứng, mà còn triệt tiêu những mối đe doạ đối với dữ liệu đang sử dụng. Nhờ vậy, các cơ quan, tổ chức có thể yên tâm rằng mô hình học máy của mình có thể sử dụng nhiều bộ dữ liệu khác nhau và huấn luyện thuật toán trong khi vẫn đảm bảo tuân thủ các quy định pháp luật và bảo mật hệ thống.
Tương lai của học liên kết
Bằng cách kích hoạt các mô hình ML thu thập kiến thức từ nhiều nguồn dữ liệu phong phú và đa dạng vốn không thể có được bằng những phương thức khác, học tập liên kết sở hữu tiềm năng đem đến những bước đột phá trong CSSK, cải thiện công tác chẩn đoán, và xử lý tốt hơn vấn đề chênh lệch y tế.
Mặc dù hiện tại chúng ta mới ở bước đầu trong học liên kết, nhưng có thể nhận thấy những tiềm năng vĩ đại trong việc đưa các cơ quan, tổ chức lại gần nhau hơn nhằm chung tay hợp tác và giải quyết nhiều thách thức lớn, đồng thời vẫn giảm thiểu nguy cơ về bảo mật dữ liệu và an ninh. Trên thực tế, học liên kết có thể mở rộng phạm vi áp dụng ra ngoài lĩnh vực CSSK, với nhiều triển vọng lớn lao trong Internet vạn vật, công nghệ tài chính, và hơn thế nữa.
Tương lai của học liên kết sẽ đưa ứng dụng AI lên một tầm cao mới, và chúng ta mới chỉ bước đầu khai thác tiềm năng thực sự của phương thức này./.

























