
Mô hình nhận dạng lời nói trong trong phát triển cơ sở dữ liệu điện tử tiếng đồng báo dân tộc thiểu số Việt - Hrê, Việt - CO
Trên địa bàn tỉnh Quảng Ngãi, có khoảng 187.000 người dân tộc thiểu số (DTTS) sinh sống chủ yếu là Hrê và Co, chiếm 13,32% tổng dân số toàn tỉnh. Trong khi đó người Kinh đến công tác, giảng dạy, làm việc tại các huyện miền núi có người đồng bào dân tộc sinh sống, trong giao tiếp là một trở ngại lớn, cần phải học tiếng để có thể giao tiếp được với người bản địa.
Việc nghiên cứu, xây dựng cơ sở dữ liệu (CSDL) điện tử tiếng đồng bào DTTS Việt - Hrê, Việt - Co là hết sức cần thiết nhằm thu hẹp khoảng cách giao tiếp giữa người Hrê, Co và người Kinh. Bên cạnh đó góp phần gìn giữ cho các thế hệ sau không chỉ ngôn ngữ mà còn những giá trị văn hoá truyền thống đặc sắc của người đồng bào dân tộc tỉnh Quảng Ngãi.
Hiện nay, công nghệ nhận diện lời nói bằng AI cho tiếng Việt và nhiều ngôn ngữ khác trên thế giới, đã đạt được những kết quả có độ chính xác rất cao. Do đó, có thể ứng dụng công nghệ này trong việc nhận diện tiếng Việt trong chiều dịch Việt - Hrê và Việt - Co của CSDL điện tử. Tuy nhiên, đối với chiều ngược lại - nhận dạng lời nói trong tiếng đồng bào DTTS, cụ thể là Hrê và Co rồi dịch sang tiếng Việt vẫn chưa được tiếp cận và nghiên cứu trước đây. Bài viết sẽ mô tả kết quả đã nghiên cứu và thực hiện thành công việc xây dựng mô hình nhận dạng lời nói tiếng Hrê và Co để ứng dụng vào CSDL điện tử tiếng đồng bào dân tộc thiểu số Việt - Hrê, Việt - Co.
Đặt vấn đề
Hiện nay, trên địa bàn tỉnh Quảng Ngãi có dân số 1.231.697 người gồm trên 30 dân tộc sinh sống. Trong đó, có khoảng 187 nghìn người dân tộc thiểu số sinh sống, chủ yếu là Hrê và Co, chiếm 13,32% tổng dân số toàn tỉnh. Người Hrê và Co phần lớn phân bố ở các huyện Ba Tơ, Minh Long, Sơn Hà, Sơn Tây và Trà Bồng.
Trong những năm qua, với sự quan tâm của các cấp ngành có liên quan, Sở Nội vụ tỉnh Quảng Ngãi phối hợp với Trường Đại học Phạm
Văn Đồng hằng năm đều tổ chức các lớp giảng dạy tiếng đồng bào DTTS (cụ thể là tiếng Hrê và tiếng Co) cho đối tượng cán bộ công chức, viên chức, giáo viên. Tuy nhiên, chưa có CSDL tiếng đồng bào DTTS nào được biên soạn, xây dựng để phục vụ việc tra cứu ngôn ngữ trong quá trình học mà chỉ có các tài liệu giáo trình giảng dạy, tài liệu nghiên cứu của các nhóm tác giả.
Vì vậy, nghiên cứu, xây dựng CSDL điện tử tiếng đồng bào DTTS Việt - Hrê, Việt - Co là hết sức cần thiết nhằm thu hẹp khoảng cách giao tiếp, ngôn ngữ, giúp cho người đồng bào dân tộc thiểu số học hỏi, nâng cao kiến thức, hòa nhập với sự phát triển chung của tỉnh, của đất nước; đồng thời qua đó truyền đạt các kiến thức, các chủ trương, chính sách của chính quyền đến người đồng bào, tiếp thu kinh nghiệm và hiểu rõ các vấn đề của người đồng bào được sâu sắc hơn.
Xây dựng CSDL điện tử tiếng đồng bào DTTS Việt - Hrê, Việt - Co cũng là một hình thức số hóa tiếng đồng bào DTTS của tỉnh Quảng Ngãi. Việc thu thập, lưu trữ để xây dựng kho dữ liệu ngữ vựng dạng số của tiếng Hrê, Co không chỉ giúp cho người bản ngữ có ý thức bảo tồn, phát triển tiếng mẹ đẻ, mà còn hình thành một kho tài nguyên thông tin đầy đủ, chân thực, giúp cho các nghiên cứu hiện tại và sau này có tư liệu chính xác. Đồng thời, góp phần gìn giữ cho các thế hệ sau không chỉ ngôn ngữ mà còn những giá trị văn hóa truyền thống đặc sắc của người đồng bào dân tộc tỉnh Quảng Ngãi.
Trên cơ sở nguồn dữ liệu tiếng Hrê và tiếng Co tại 2 bộ tài liệu đã được UBND tỉnh Quảng Ngãi phê duyệt, thực hiện việc số hóa đồng nhất giữa các từ tương ứng để thành lập một kho dữ liệu Việt - Hrê, Việt - Co. CSDL gồm: Kho ngữ vựng song ngữ Việt - Hrê và ngược lại; Kho ngữ vựng song ngữ Việt - Co và ngược lại;
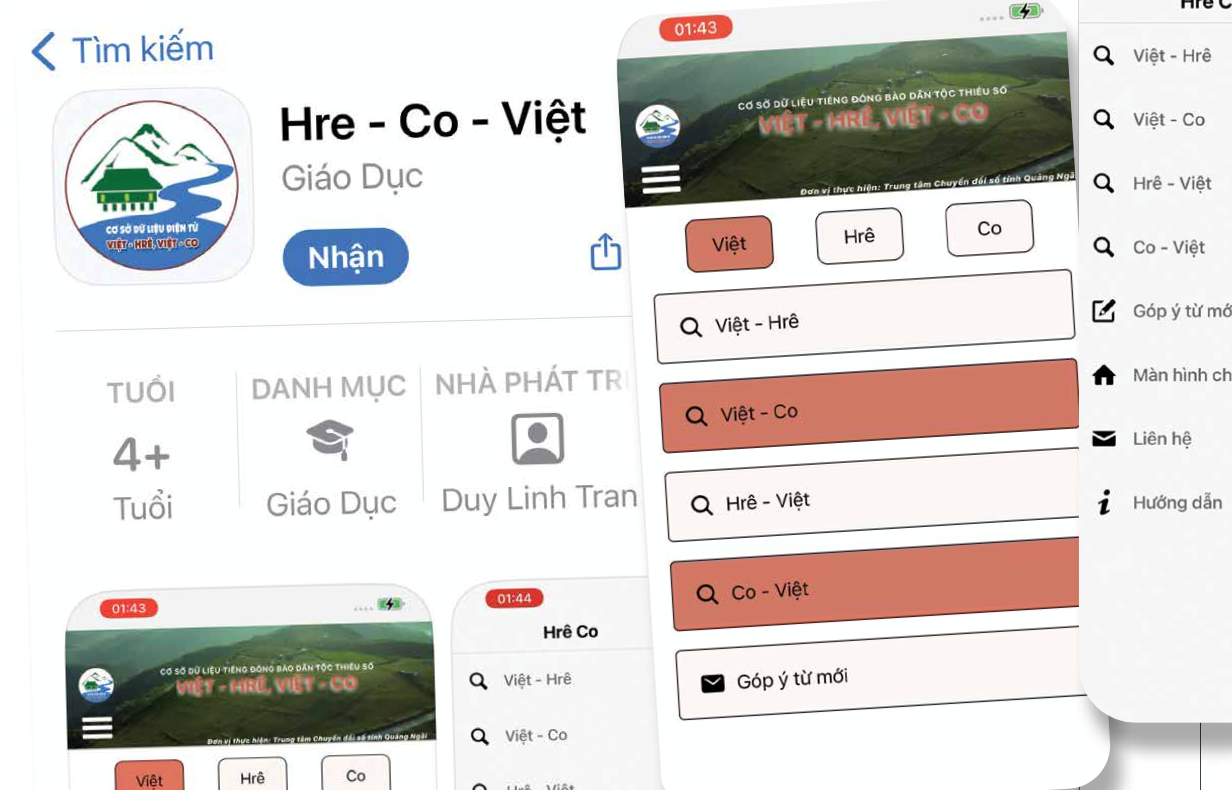
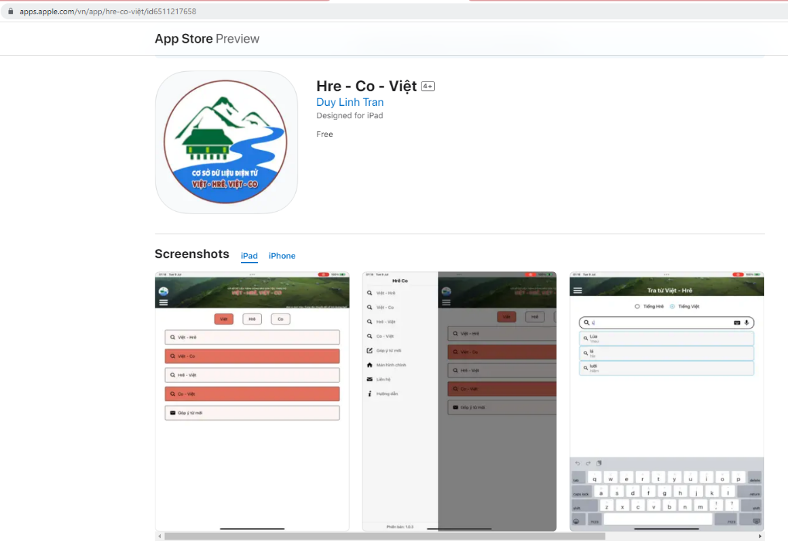
Nhờ vào kho dữ liệu đã xây dựng, nhóm đề tài đã phát triển thành công bộ phần mềm CSDL điện tử có thể sử dụng được trên các thiết bị điện tử như: máy tính, điện thoại thông minh... nhằm mục đích tra ngữ nghĩa giữa các ngôn ngữ Việt - Hrê, Việt - Co. Phần mềm trang bị thêm phân hệ chức năng để người dùng có thể cập nhật thêm một số từ chưa có trong CSDL. Bộ phần mềm CSDL điện tử Việt - Hrê, Việt - Co gồm các phiên bản chạy trên web [1] và ứng dụng (app) “Hrê - Co - Việt” chạy trên thiết bị di động Android và IOS.
Hiện nay, các công nghệ AI (Artificial Intelligence) đang phát triển mạnh mẽ cùng với những tiến bộ đồng thời về sức mạnh máy tính, dữ liệu lớn và hiểu biết lý thuyết; AI đã trở thành một phần thiết yếu của nhiều ngành và công nghệ, giúp giải quyết nhiều vấn đề thách thức trong học máy, công nghệ phần mềm, nghiên cứu vận hành, đặc biệt trong ngôn ngữ và nhận dạng lời nói.
Trong đó, đối với tiếng Việt và nhiều ngôn ngữ khác trên thế giới, công nghệ nhận diện lời nói (hay nhận dạng tiếng nói, Automatic speech recognition - ASR) bằng AI đã đạt được những kết quả với độ chính xác rất cao, cho phép nhận dạng tiếng nói và tự động chuyển tiếng nói thành văn bản điện tử (Speech To Text). Trên cơ sở đó, có thể ứng dụng công nghệ này trong việc nhận diện tiếng Việt trong chiều dịch Việt - Hrê và Việt - Co của CSDL điện tử.
Tuy nhiên, đối với chiều ngược lại - nhận dạng lời nói tiếng đồng bào DTTS, cụ thể là Hrê và Co rồi dịch sang tiếng Việt vẫn chưa từng được tiếp cận, nghiên cứu trước đây. Với những thành tựu và xu hướng phát triển của công nghệ AI hiện nay, đặc biệt là khả năng huấn luyện thông qua “học sâu” (deep learning), các tác giả đã nghiên cứu và thực hiện thành công việc xây dựng mô hình nhận dạng lời nói tiếng Hrê và Co để ứng dụng vào CSDL điện tử tiếng đồng bào dân tộc thiểu số Việt - Hrê, Việt - Co.
Mô hình ứng dụng công nghệ nhận dạng lời nói vào CSDL điện tử
Mô hình nhận dạng lời nói bằng AI (và học sâu) đã nghiên cứu thành công và ứng dụng vào CSDL điện tử tiếng đồng bào dân tộc thiểu số Việt - Hrê, Việt - Co như Hình 1.
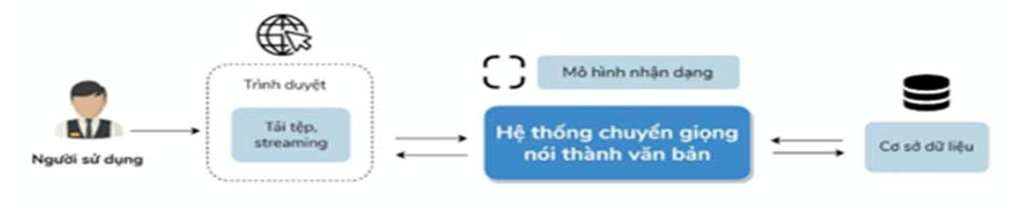
Trong đó:
- Người sử dụng nói trực tiếp hoặc gửi tệp (file) âm thanh lên.
- Hệ thống nhận diện và chuyển lời nói sang văn bản, sau đó chuyển từ cần truy vấn đến CSDL.
- CSDL truy vấn lấy kết quả và trả kết quả (nếu tìm thấy) cho người dùng ở dạng văn bản. Nếu không tìm thấy từ vựng tương ứng, hệ thống sẽ đề xuất các từ vựng tương tự, gần giống nhất với từ được nhận diện bởi mô hình.
Ứng dụng nhận dạng lời nói vào CSDL điện tử tiếng đồng bào dân tộc thiểu số Việt - Hrê, Việt - Co sẽ giúp người sử dụng có thể tra cứu bằng cách “nói từ” bên cạnh cách “nhập từ”, mang lại nhiều hiệu quả cho người sử dụng như:
- Khả năng truy cập: Đây là một thuận lợi đối với người biết phát âm nhưng không biết cách viết, người không rành công nghệ, hoặc người khuyết tật khi không thể dùng chuột hay bàn phím, nhưng có thể dùng giọng nói để hệ thống chuyển thành văn bản, giúp nhập liệu hay điều khiển một cách dễ dàng.
- Tốc độ nhanh: Phần mềm nhận dạng giọng nói có thể nắm bắt giọng nói của người dùng với tốc độ nhanh hơn so với khi nhập liệu bằng bàn phím, vì vậy, tốc độ khi nhập liệu bằng giọng nói sẽ cải thiện đáng kể.
Các mô hình học sâu, chẳng hạn như mạng nơ-ron sâu (deep neural networks - DNN), mạng nơ-ron tích chập (convolutional neural network - CNN) [2] đã cải tiến quá trình xử lý giọng nói bằng cách tự động học các đặc trưng có ý nghĩa từ tín hiệu giọng nói thô, cải thiện độ chính xác trong các ứng dụng khác nhau [3]stop, forward, backward, right, left.
Tuy nhiên, trong thời gian gần đây, các mô hình nhận dạng lời nói tự động dựa trên kiến trúc máy biến áp (Transformer) [4] đã đạt được những bước đột phá trong việc xây dựng các mô hình đào tạo trước để tinh chỉnh (fine-tune) cho các tác vụ nhận dạng lời nói.
Đặc biệt, năm 2022 Alec Radford và cộng sự từ OpenAI đã phát hành Whisper [5] - một mô hình được đào tạo trước để nhận dạng giọng nói với một lượng lớn dữ liệu âm thanh (680.000 giờ) được gắn nhãn. Các điểm kiểm tra được đào tạo trước đạt được kết quả cạnh tranh với các mô hình hiện đại, thể hiện khả năng khái quát hóa mạnh mẽ cho nhiều bộ dữ liệu và lĩnh vực, với tỷ lệ lỗi từ (WER) gần 3% trên các tập hợp con đã được kiểm tra của LibriSpeech pipe và TED-LIUM với 4,7% WER [5]. Do vậy, chúng tôi quyết định sử dụng Whisper để bắt đầu huấn luyện cho các mô hình nhận dạng lời nói trong đề tài của mình.
Trên cơ sở danh mục từ tiếng Hrê và tiếng Co đã chuẩn hóa, tiến hành ghi âm phát âm từ theo danh mục và đặt tên cho file ghi âm (định dạng .mp3) theo mã số của từ trong danh mục từ. Sau khi hoàn thành, đã thu thập được bộ file âm thanh thô của danh mục từ tiếng Hrê gồm 3928 file (tương ứng với 1964 từ Hrê do giọng nam và giọng nữ đọc) và tiếng Co gồm 1050 file (tương ứng 1050 từ giọng nam).
Tiếp theo, chúng tôi sử dụng thư viện Datasets, cung cấp khả năng truy cập dễ dàng vào tuyển tập các bộ dữ liệu học máy có sẵn công khai trên nền tảng Hugging Face Hub [6]. Thư mục data chứa 2 thư mục con là train (gồm dữ liệu huấn luyện) và test (gồm dữ liệu kiểm tra).
Kết quả
Sau khi chuẩn bị xong dữ liệu, có thể thực hiện huấn luyện mô hình nhận dạng tiếng Hrê và mô hình nhận dạng tiếng Co, đạt được độ chính xác khá cao trên tập kiểm tra, với tỉ lệ lỗi ký tự CER lần lượt là 1% và 0% cho các mô hình nhận dạng tiếng Hrê và tiếng Co tương ứng, do vậy có thể ứng dụng trong chiều dịch Hrê - Việt và Co - Việt của CSDL điện tử.
Từ nguồn dữ liệu và kết quả của các nội dung nghiên cứu trước đó, chúng tôi đã xây dựng CSDL điện tử tiếng đồng bào dân tộc thiểu số Việt - Hrê, Việt - Co theo quy trình phát triển phần mềm.
Kết quả là sản phẩm CSDL điện tử tiếng đồng bào dân tộc thiểu số Việt - Hrê và Việt - Co phiên bản web và app di động. Phiên bản web của CSDL điện tử đã hoàn thành, được cài đặt và hoạt động trên môi trường mạng tại tên miền https://csdlhreco.nuian.vn, phục vụ tra cứu tiếng đồng bào dân tộc thiểu số Việt - Hrê, Việt - Co và ngược lại (Hình 2).
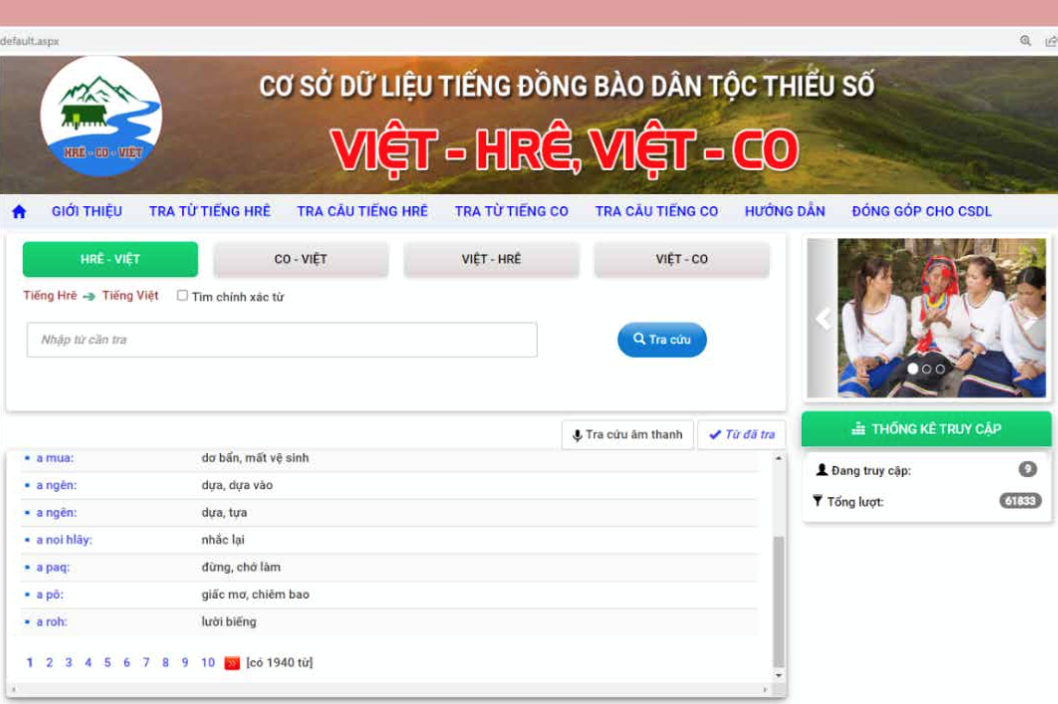
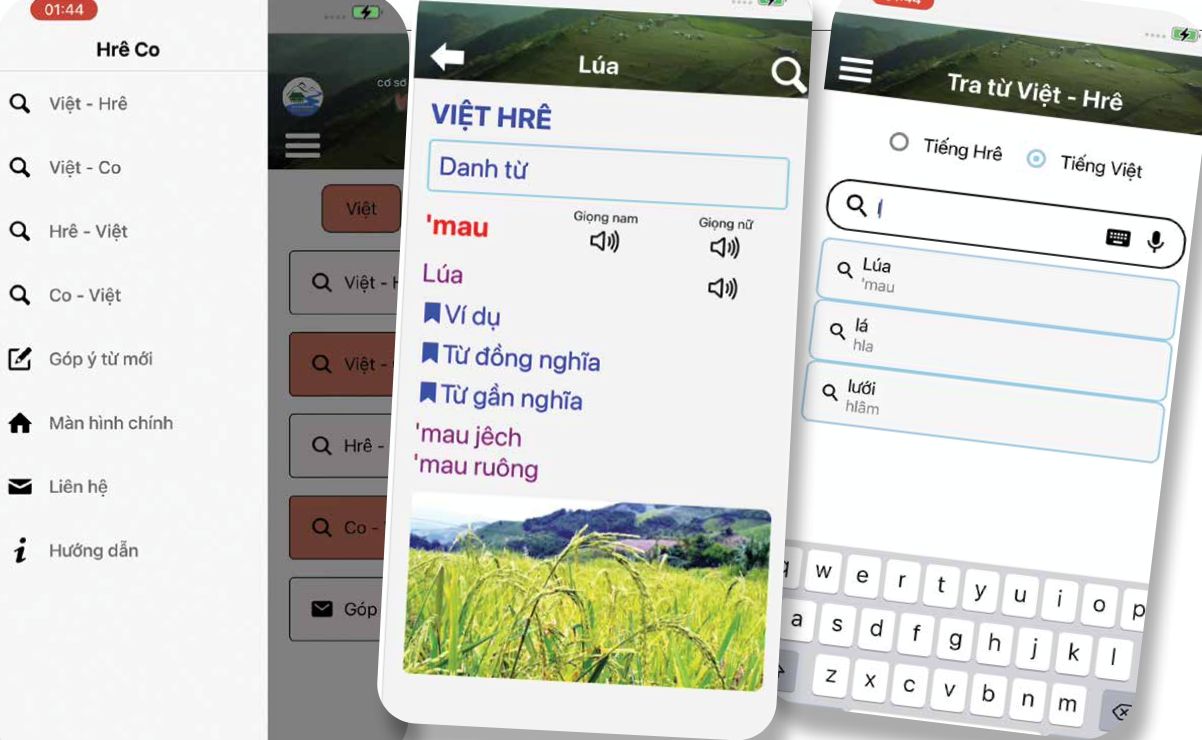
Các từ đều được dịch nghĩa, hướng dẫn phát âm, cung cấp các từ đồng nghĩa, ví dụ minh họa, có hình ảnh về phong tục, tập quán, văn hóa của người đồng bào DTTS Hrê, Co. CSDL điện tử được thiết kế linh hoạt, cho phép khai thác và sử dụng trên nhiều hệ thống: máy vi tính, điện thoại thông minh, máy tính bảng; cung cấp đầy đủ chức năng để tra cứu từ thông qua bộ gõ ký tự hoặc giọng nói với chức năng thêm mới, cập nhật, chỉnh sửa từ ngữ, cập nhật hình ảnh; đồng thời có chức năng cho phép tiếp nhận phản hồi và tương tác với người dùng qua chức năng “Đóng góp cho CSDL”.
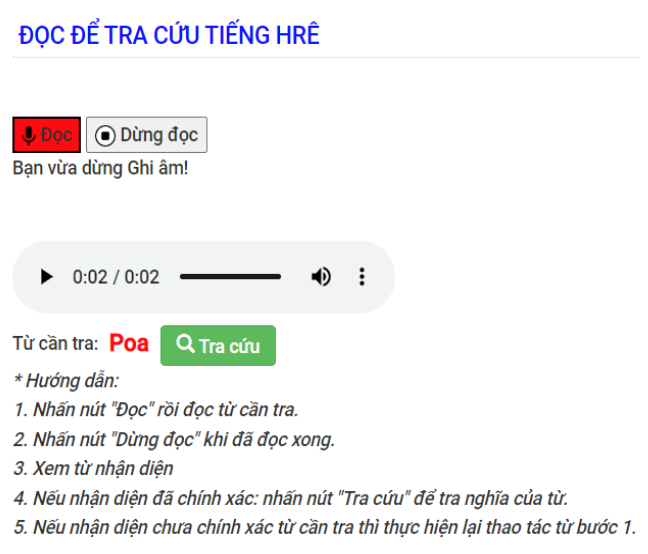
Sau khi luấn luyện các mô hình nhận dạng lời nói tiếng Hrê/Co thành công có thể tiến thành tích hợp vào CSDL điện tử. Đầu tiên cần dựng form trên website cho phép đọc âm thanh, ghi âm rồi chuyển file ghi âm vào mô hình nhận dạng tiếng Hrê/ Co thông qua API request, sau đó lấy kết quả nhận diện (dạng text) trả về, như trong Hình 3. Tiếp theo, kết quả này được sử dụng để làm input cho hàm tra cứu từ tiếng Hrê/Co đã tích hợp vào phần mềm CSDL điện tử ở phiên bản web và app, cho phép nhận diện tiếng Hrê và Co để tra từ.
Tương tự, thực hiện xây dựng app hoạt động trên các thiết bị di động gồm các bước theo quy trình xây dựng app, bao gồm: Thiết kế, hiệu chỉnh giao diện app; Lập trình chức năng app (bao gồm app trên Android và iOS); Kiểm thử và hiệu chỉnh app; Cài đặt app trên Android và iOS. Kết quả là ứng dụng “Hre - Co - Việt” đã hoàn thiện, tích hợp module nhận diện lời nói Hre/Co, được phát hành trên các kho ứng dụng lớn Google Play và Apple Store (Hình 4).
Kết luận
Hiện nay, AI đã có nhiều ứng dụng rộng rãi trong nhiều lĩnh vực, trong đó có lĩnh vực từ điển điện tử với công nghệ nhận diện lời nói. Tuy nhiên, việc nhận diện lời nói tiếng đồng bào dân tộc thiểu số Hrê, Co vẫn chưa từng có trước đây, nên kết quả trong bài báo này là một nghiên cứu mới, vừa mang lại hiệu quả thiết thực với sản phẩm, và sẽ là nền tảng cho các nghiên cứu khác liên quan đến ứng dụng công nghệ vào lĩnh vực ngôn ngữ.
Trong bài viết này, chúng tôi đã sử dụng mô hình Whisper small để thực hiện tiền xử lý bằng thư viện Datasets trên bộ dữ liệu đầy đủ tiếng Hrê và tiếng Co. Sau đó thực hiện tinh chỉnh huấn luyện được mô hình nhận dạng tiếng Hre là whisper-small-hre4.4 https://huggingface. co/ntviet/whisper-small-hre4.4 (CER 1%, trải nghiệm mô hình tại https://csdlhreco.nuian.vn/ aihre.aspx và app “Hre - Co - Việt”). Tương tự, đã huấn luyện thành công mô hình nhận dạng tiếng Co whisper-small-co https://huggingface.co/ ntviet/whisper-small-co (CER 0%, trải nghiệm mô hình tại địa chỉ https://csdlhreco.nuian.vn/ aico.aspx và app “Hre - Co - Việt”).
Các mô hình ASR cho tiếng Hrê và tiếng Co giờ đây đã có thể ứng dụng vào CSDL điện tử tiếng đồng bào dân tộc thiểu số Việt - Hrê, Việt - Co, giúp mang lại nhiều hiệu quả thiết thực cho người sử dụng CSDL điện tử. Việc nghiên cứu, xây dựng CSDL điện tử tiếng đồng bào dân tộc thiểu số Việt - Hrê, Việt - Co là cần thiết và mang lại nhiều lợi ích, giá trị to lớn cho cộng đồng.
Đây sẽ là nơi lưu giữ ngôn ngữ truyền thống của các dân tộc thiểu số trên địa bàn tỉnh, đồng thời qua đó cũng sẽ lưu giữ các giá trị văn hóa truyền thống, hình ảnh, phong tục, tập quán và văn hóa của người Hrê, Co, góp phần bảo tồn và phát huy các giá trị truyền thống độc đáo của mỗCi dân tộc, cùng hòa vào dòng chảy chuyển đổi số chung của tỉnh nói riêng và đất nước nói chung.
Tài liệu tham khảo:
1. “Cơ sở dữ liệu tiếng đồng bào dân tộc thiểu số Việt - Hre, Việt - Co”., available at: https://csdlhreco.nuian.vn (truy cập 25 Tháng Sáu 2024a).
2. Mehrish, A., Majumder, N., Bharadwaj, R., và c.s. (2023b), “A review of deep learning techniques for speech processing”, Information Fusion, Vol. 99, tr 101869, doi: 10.1016/j.
inffus.2023.101869.
3. Alsobhani, A., ALabboodi, H.M.A. và Mahdi, H. (2021c), “Speech Recognition using Convolution Deep Neural Networks”, Journal of Physics: Conference Series, Vol. 1973 No. 1,
tr 012166, doi: 10.1088/1742-6596/1973/1/012166.
4. Vaswani, A., Shazeer, N., Parmar, N., và c.s. (2017d), “Attention Is All You Need”, Advances in Neural Information Processing Systems.
5. Radford, A., Kim, J.W., Xu, T., và c.s. (2022e), “Robust Speech Recognition via Large-Scale Weak Supervision”, Proceedings of Machine Learning Research.
6. “Create a new dataset repository”., available at: https://huggingface.co/new-dataset (truy cập 25 Tháng Sáu 2024f).
(Bài viết đăng ấn phẩm in Tạp chí TT&TT số 9 tháng 9/2024)













 - Xu hướng thế giới và khuyến nghị đối với Việt Nam")




![[Podcast] Phát triển khoa học công nghệ, ĐMST và CĐS phải hướng đến kết quả cuối cùng](https://ictv.1cdn.vn/thumbs/540x360/2025/07/17/a1.jpg "[Podcast] Phát triển khoa học công nghệ, ĐMST và CĐS phải hướng đến kết quả cuối cùng")




