
Định hướng xử lý tiếng dân tộc Hrê và dân tộc Co, ứng dụng xây dựng kho ngữ vựng song ngữ Việt-Hrê, Hrê-Việt, Việt-Co và Co-Việt
Nhiều ngôn ngữ dân tộc thiểu số (DTTS) có nguy cơ mai một do sự đan xen và giảm dần số người sử dụng.
Tóm tắt:
- Mục tiêu: Xây dựng kho ngữ vựng song ngữ Việt-Hrê, Hrê-Việt, Việt-Co, và Co-Việt để bảo tồn ngôn ngữ các dân tộc thiểu số Hrê và Co.
- Hiện trạng ngôn ngữ DTTS: Nhiều ngôn ngữ dân tộc thiểu số (DTTS) có nguy cơ mai một do sự đan xen và giảm dần số người sử dụng.
- Thách thức trong xử lý ngôn ngữ: Thiếu tài nguyên dữ liệu điện tử, nguồn tài chính, và hệ thống mã hóa chữ viết cho các ngôn ngữ DTTS.
- Quy trình xử lý: Gồm 4 giai đoạn xây dựng từ vựng, công cụ phân tích, môi trường xử lý nâng cao, và ứng dụng tìm kiếm dịch thuật.
- Sử dụng Blockchain: Đảm bảo tính toàn vẹn và an toàn dữ liệu trong quá trình quản lý và chia sẻ kho ngữ vựng.
- Kết quả thực nghiệm: Đã xây dựng và cập nhật thành công các kho ngữ vựng với hơn 3.000 mục từ cho Hrê và hơn 1.000 mục từ cho Co.
Đặt vấn đề
Hiện nay đã có một số ngôn ngữ, chữ viết DTTS được sử dụng trên các phương tiện thông tin đại chúng từ trung ương tới địa phương, như: Tày, Thái, Dao, Mông, Gia Rai, Ê Đê, Ba Na, Chăm, Khơ Me… Nhiều địa phương đã triển khai thực hiện dạy tiếng dân tộc cho học sinh trong trường phổ thông. Trong những năm qua việc nghiên cứu xử lý tiếng DTTS đã đạt được những kết quả sau:
- Bộ gõ tiếng Chăm Multilingual Edit của Trương Kỳ Quốc, lớp 20TLĐ, Đà Lạt, 2002.
- Bộ gõ tiếng dân tộc của kĩ sư Trương Đình Tú, STVB bốn ngôn ngữ DTTS Ê Đê, Gia Rai, Ba Na, M’Nông và tiếng Việt [1].
- Chương trình TayNguyenKe hỗ trợ gõ chữ các dân tộc thiểu số Tây Nguyên của nhóm các tác giả: Tiến sĩ Y Ghi Niê, Kỹ sư Võ Ngọc Hiệp, Thạc sĩ Trần Cát Lâm. TayNguyenKey có thể gõ được 6 thứ tiếng dân tộc thiểu số Tây Nguyên: Ê Đê, Gia Rai, Ba Na, Xê Đăng, Cơ Ho và M’Nông.
Ngoài ra còn gõ được tiếng Việt và tiếng Anh [2].
- Bộ gõ VnKey của tác giả Trần Thanh Bình hỗ trợ gõ tiếng Việt và ngôn ngữ của dân tộc thiểu số Việt Nam như: Ê Đê, Gia Rai, M’Nông, Cơ Ho, Xê Đăng, Sán Chay…
- Từ điển điện tử Việt-Ê Đê do Đài Tiếng nói Việt Nam khu vực Tây Nguyên thực hiện, nhằm phục vụ việc tra cứu trong quá trình dịch thuật từ tiếng Việt sang tiếng Ê Đê và ứng dụng trong công tác dịch, đọc của chương trình phát thanh tiếng Ê Đê tại Cơ quan thường trú. Từ điển điện tử phương ngữ Gia Rai-Việt, đề tài khoa học của Sở Thông tin và Truyền thông tỉnh Gia Lai. Từ điển điện tử M’Nông-Việt, Việt-M’Nông của Sở Khoa học và Công nghệ Đăk Nông.
Với những kết quả đạt được về nghiên cứu xử lý tiếng DTTS trên, những khó khăn để tiếp tục nghiên cứu từ các kết quả nghiên cứu xử lý tiếng DTTS: Chưa có các kết quả nghiên cứu cho xử lý tiếng DTTS Hrê và tiếng DTTS Co. Vì vậy, định hướng xử lý tiếng dân tộc Hrê và dân tộc Co ứng dụng xây dựng kho ngữ vựng song ngữ Hrê-Việt, Việt-Hrê, Việt-Co và Co-Việt làm hạ tầng cơ sở cho xử lý tiếng Hrê và tiếng Co là rất cấp thiết.
Thực trạng tiếng DTTS ở Việt Nam
Ngôn ngữ dân tộc Việt Nam
Nước ta, tiếng Việt bao gồm cách phát âm tiếng Việt và chữ Quốc ngữ để viết là ngôn ngữ của người Việt (người Kinh) đang được dùng chính thức trong toàn quốc. Tiếng Việt được chính thức ghi nhận trong hiến pháp là ngôn ngữ quốc gia của Việt Nam. Đây là tiếng mẹ đẻ của gần 86% dân cư Việt Nam, cùng với hơn bốn triệu người Việt ở nước ngoài. Tiếng Việt còn là ngôn ngữ thứ hai của các DTTS Việt Nam và là một phương tiện giao tiếp trong các cơ quan của đại chúng; trong các hoạt động nghiên cứu khoa học, sáng tác, xuất bản văn học nghệ thuật. Mặc dù các dân tộc đều có ngôn ngữ riêng nhưng vẫn xem tiếng Việt là ngôn ngữ của mình. Chính sách song ngữ là một biểu hiện tính thống nhất và đa dạng trong ngôn ngữ của các dân tộc Việt Nam.
Với đặc điểm đa dạng về tộc người nên Việt Nam cũng là quốc gia đa ngôn ngữ. Dân tộc Việt Nam nói các ngôn ngữ khác nhau. Ngoài dân tộc Kinh là dân tộc chiếm gần 86% dân số, còn có 54 dân tộc khác, thuộc các ngữ hệ khác nhau thể hiện trong Bảng 1.
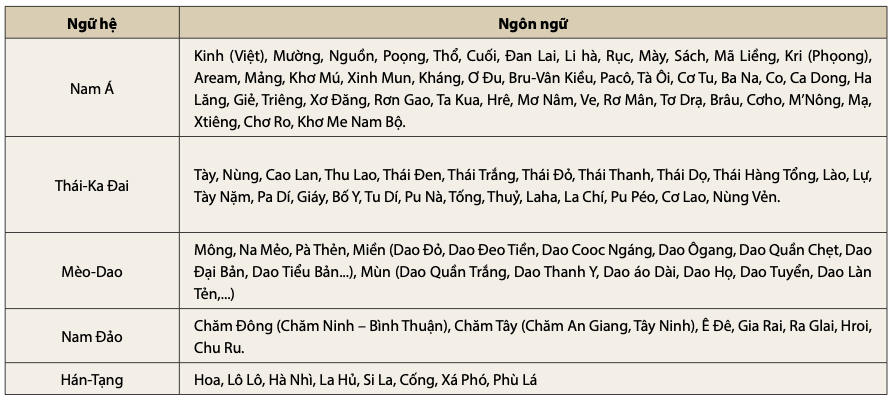
Đặc điểm nổi bật của các DTTS Việt Nam là sống đan xen nhau làm cho trạng thái đa ngữ xã hội là trạng thái phổ biến ở các vùng DTTS. Tiếng Việt được xem là ngôn ngữ giao tiếp giữa các dân tộc. Tuy nhiên, ngôn ngữ của các DTTS vẫn có vị trí và tác dụng trong mỗi vùng.
Nguy cơ mai một ngôn ngữ DTTS
Với 55 dân tộc trên đất nước Việt Nam và có khoảng hơn 90 ngôn ngữ khác nhau. Mỗi dân tộc đều có ngôn ngữ của riêng mình. Tuy nhiên, xu hướng hội nhập quốc tế là nguy cơ giảm các ngôn ngữ DTTS.
Chữ viết của mỗi dân tộc thể hiện sự phát triển cao về mặt văn hóa, trình độ phát triển tư duy và nền văn minh. Văn hóa của các dân tộc Việt Nam có nhiều nét tương đồng, nhưng về cơ bản các DTTS vẫn tồn tại một nền văn hóa mang bản sắc riêng; trình độ phát triển kinh tế, văn hóa giữa các dân tộc không đồng đều. Một số DTTS có chữ viết từ rất lâu đời, nhưng nhiều dân tộc khác lại không có chữ viết riêng. Ngôn ngữ DTTS mất dần sự trong sáng vốn có và bị pha tạp tiếng Việt.
Một số nguyên nhân dẫn đến nguy cơ mai một ngôn ngữ DTTS:
- Số lượng người nói một ngôn ngữ trong một đơn vị địa lý, hành chính không cao và không tập trung vì các DTTS ở Việt Nam thường sống đan xen nhau.
- Sự nói bồi lẫn nhau làm cho ngôn ngữ các DTTS nghèo đi và sẽ dẫn tới nguy cơ mai một. Điều này thể hiện rất rõ ở chỗ ngày càng có nhiều người nói được bằng lời nhưng lại không hiểu được văn bản khi đọc, dẫn tới tư duy chậm chạp.
- Số người nói được các ngôn ngữ DTTS thường thuộc lứa tuổi già và trung niên, còn lứa tuổi thanh niên biết tiếng mẹ đẻ ít hơn, thậm chí còn rất nhiều trẻ em không biết tiếng mẹ đẻ của mình.
- Các hệ thống ngôn ngữ DTTS có phạm vi sử dụng rất hẹp và có chưa được nhiều người biết đến. Phần lớn các ngôn ngữ DTTS không được truyền dạy có tổ chức mà chỉ được truyền dạy tự phát, hay dùng trong phạm vi gia đình, bản làng...
Trước thực trạng tiếng nói của các DTTS đang đứng trước nguy cơ mai một, cộng đồng các dân tộc Việt Nam và Chính phủ cần có những chương trình như khuyến khích, vận động nhân dân các dân tộc giao tiếp hằng ngày bằng tiếng mẹ đẻ, xây dựng các kho ngữ vựng song ngữ giữa tiếng Việt và tiếng DTTS nói chung và cụ thể ở đây là Hrê- Việt, Việt-Hrê, Việt-Co và Co-Việt để bảo tồn.
Khó khăn và thách thức
Trong xử lý ngôn ngữ DTTS khó khăn đặt ra đầu tiên là phải mã hóa thích hợp hệ thống chữ viết các DTTS trong Unicode và phải phù hợp với bàn phím tiếng Anh, bởi vì các DTTS thường có hệ thống chữ viết của riêng mình.
Xử lý ngôn ngữ DTTS thường xuyên phải đối mặt với khó khăn đầu ti ên đó là bộ chữ cái tiếng DTTS đã có trong Unicode hay chưa, tiếp theo là thiếu nguồn tài nguyên dữ liệu chuẩn hóa dưới dạng điện tử, chuyên môn. Chính sự khan hiếm nguồn tài nguyên dữ liệu là một hạn chế cho phương pháp tiếp cận hướng dữ liệu trong xử lý ngôn ngữ DTTS. Khó khăn cũng phải được kể đến đó là thiếu sự hỗ trợ về tài chính dành cho các hoạt động nghiên cứu xử lý ngôn ngữ DTTS.
Mặt khác, xử lý ngôn ngữ DTTS còn phải vượt qua một số khó khăn phát sinh từ những thực trạng đặc biệt của ngôn ngữ DTTS vì chỉ có nhóm ít người dùng, không có đủ nguồn nhân lực chuyên môn, rất ít các nhà ngôn ngữ học DTTS và các nhà khoa học máy tính là người DTTS. Chính vì vậy, việc áp dụng các phương pháp tiếp cận dựa trên luật để gán nhãn, phân tích cú pháp... có thể rất khó khăn.
Định hướng xử lý tiếng DTTS Hrê và tiếng DTTS Co
Trong xử lý ngôn ngữ tự nhiên nói chung và xử lý ngôn ngữ DTTS Hrê và DTTS Co ở Việt Nam nói riêng, việc xây dựng hạ tầng cơ sở cho xử lý ngôn ngữ là rất cần thiết nhằm tạo ra bất kỳ một công cụ kỹ thuật hay ứng dụng liên quan đến xử lý ngôn ngữ. Thông qua các hoạt động nghiên cứu của các nhóm SALTMIL, MILLE, EMILLE, xử lý ngôn ngữ Basque [3], [4], [5], [6], [7] cho thấy qui trình nghiên cứu xử lý ngôn ngữ DTTS Hrê và DTTS Co được thực hiện qua 4 giai đoạn:
Giai đoạn đầu tiên là xây dựng hạ tầng cơ sở, cụ thể: mã Unicode hệ thống chữ viết, xây dựng cơ sở dữ liệu (CSDL) từ vựng và xây dựng từ điển máy tính.
Giai đoạn thứ hai là xây dựng các công cụ kỹ thuật trong XLNNTN, cụ thể: công cụ thống kê trong xây dựng kho ngữ liệu, công cụ phân tích hình thái học, công cụ kiểm tra và sửa lỗi chính tả, công cụ xử lý tiếng nói ở mức từ, công cụ gán nhãn từ loại trong các kho ngữ liệu.
Giai đoạn thứ ba là xây dựng các công cụ kỹ thuật và các ứng dụng nâng cao, cụ thể: môi trường để tích hợp các công cụ, thu thập dữ liệu từ website, kiểm tra ngữ pháp, nâng cấp các phiên bản từ điển, kho ngữ vựng đa ngữ, xử lý tiếng nói ở mức câu.
Giai đoạn thứ tư là vấn đề về đa ngữ và các ứng tổng quát, cụ thể: tìm kiếm và khai thác thông tin, dịch máy, từ điển trực tuyến và các ứng dụng liên quan đến mối quan hệ giữa từ vựng và ngữ nghĩa đa ngữ.
Xây dựng kho ngữ vựng song ngữ Việt-Hrê, Hrê-Việt, Việt-Co và Co-Việt
Hiện nay, các nguồn dữ liệu song ngữ dân tộc Hrê, dân tộc Co chủ yếu là ở dạng từ điển giấy. Vì vậy, trong xử lý ngôn ngữ DTTS, việc hợp nhất các nguồn dữ liệu từ điển giấy trong xây dựng kho ngữ vựng song ngữ Việt-Hrê, Hrê-Việt, Việt-Co và Co-Việt là thật sự cần thiết.
Tổ chức kho ngữ vựng (KNV) song ngữ
Tiêu chí dữ liệu KNV song ngữ Việt-Hrê và Hrê-Việt
Với mục tiêu, xây dựng KNV song ngữ Việt- Hrê và Hrê-Việt làm hạ tầng cơ sở cho môi trường
xử lý tiếng Hrê. Các tiêu chí dữ liệu được đặt ra trong kho ngữ vựng như sau:
- Các từ tiếng Hrê chủ yếu được thu thập và ghi theo tiếng Hrê địa phương vốn được xem dễ nghe và dễ hiểu nhất. Các mục từ tiếng Hrê phản ánh phần nào vốn văn hóa truyền thống của người Hrê. Tiếng Hrê được ghi bằng chữ Hrê.
- Các từ tiếng Việt là từ tiếng Việt phổ thông và được ghi bằng chữ Quốc ngữ.
- Các ví dụ được đưa vào để làm rõ nghĩa và cách sử dụng của mục từ hay còn gọi là ngữ cảnh của mục từ.
- Các mục từ được gán nhãn từ loại: gán nhãn N cho danh từ, gán nhãn V cho động từ, gán nhãn A cho tính từ, gán nhãn O cho các mục từ không phải là danh từ, động từ hay tính từ.
- Từ đa nghĩa được ghi nhận, dịch và đối chiếu với các từ khác nhau tương đương trong ngôn ngữ đích.
- Khi gióng hàng từ của ngôn ngữ nguồn, tìm từ tương đương trong ngôn ngữ đích, trên cơ sở nghĩa cơ bản, nghĩa thường dùng hiện nay ở cả hai ngôn ngữ.
- Dữ liệu được lưu trên máy với phông chữ Unicode.
Tiêu chí dữ liệu KNV song ngữ Việt-Co và Co-Việt
Với mục tiêu, xây dựng KNV song ngữ Việt- Co và Co-Việt làm hạ tầng cơ sở cho môi trường xử lý tiếng Co. Các tiêu chí dữ liệu được đặt ra trong kho ngữ vựng như sau:
- Các từ tiếng Co chủ yếu được thu thập và ghi theo tiếng Co địa phương vốn được xem dễ nghe và dễ hiểu nhất.
- Các từ tiếng Việt là từ tiếng Việt phổ thông và được ghi bằng chữ Quốc ngữ.
- Các ví dụ được đưa vào để làm rõ nghĩa và cách sử dụng của mục từ hay còn gọi là ngữ cảnh của mục từ.
- Các mục từ được gán nhãn từ loại: gán nhãn N cho danh từ, gán nhãn V cho động từ, gán nhãn A cho tính từ, gán nhãn O cho các mục từ không phải là danh từ, động từ hay tính từ.
- Từ đa nghĩa được ghi nhận, dịch và đối chiếu với các từ khác nhau tương đương trong ngôn ngữ đích.
- Khi gióng hàng từ của ngôn ngữ nguồn, tìm từ tương đương trong ngôn ngữ đích, trên cơ sở nghĩa cơ bản, nghĩa thường dùng hiện nay ở cả hai ngôn ngữ.
- Dữ liệu được lưu trên máy với phông chữ Unicode.
Cấu trúc KNV
Tổ chức cấu trúc KNV là bước quan trọng trong xây dựng KNV. Trong nghiên cứu này, KNV được thiết kế theo mô hình CSDL quan hệ. CSDL quan hệ được sử dụng như một tập hợp các bảng lưu trữ dữ liệu và lưu trữ một tập hợp các thực thể có quan hệ với nhau. Các bảng CSDL tương tự như một KNV, được lưu trữ hoàn toàn độc lập về cấu trúc cũng như về dữ liệu. Mô hình CSDL quan hệ có những ưu điểm và nhược điểm sau:
Ưu điểm: CSDL quan hệ là một KNV riêng biệt, có khả năng linh hoạt rất cao, ít lập trình để truy cập CSDL hơn các CSDL khác. Độc lập về cấu trúc CSDL, do đó, người sử dụng và người thiết kế hoàn toàn không phải quan tâm tới cấu trúc CSDL. Dễ tạo ra một giao diện thích hợp với người sử dụng.
Nhược điểm: CSDL quan hệ che hết gần như toàn bộ cấu trúc vật lý của CSDL. Do đó, cần phải có phải có hệ điều hành và một hệ thống máy tính đủ mạnh để hỗ trợ cho việc thực hiện những thao tác truy cập dữ liệu.
Tuy nhiên, các KNV song ngữ Việt-Hrê, Hrê- Việt, Việt-Co, Co-Việt với số mục từ không quá lớn, cùng với cấu hình máy tính ngày càng được phát triển và sự hỗ trợ của công nghệ cao, thì nhược điểm này cũng được chấp nhận.
Mô hình hợp nhất nguồn dữ liệu song ngữ
Xuất phát từ thực trạng KNV song ngữ Việt- Hrê, Hrê-Việt, Việt-Co, Co-Việt để giải quyết bài toán xây dựng các KNV song ngữ Việt-Hrê, Hrê- Việt, Việt-Co, Co-Việt với nguồn dữ liệu đầu vào chủ yếu là các từ điển giấy Hrê-Việt, Co-Việt. Bài viết đề xuất mô hình hợp nhất nguồn dữ liệu song ngữ từ điển giấy Hrê-Việt, Co-Việt trong xây dựng các KNV song ngữ Việt-Hrê, Hrê-Việt, Việt-Co, Co-Việt.
Mô hình hợp nhất nguồn dữ liệu song ngữ được thể hiện trong Hình 1.
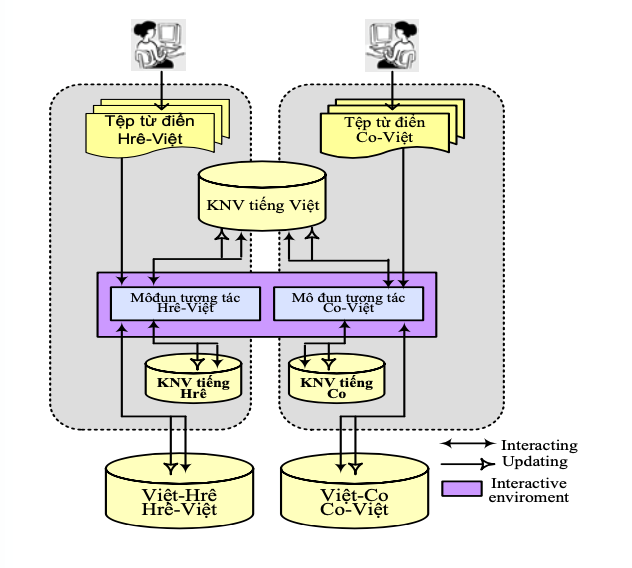
Hoạt động của module tương tác Hrê-Việt
Trình từ thực hiện
Bước 1: đọc dữ liệu trên mỗi hàng trong tệp từ điển Hrê-Việt (từ tiếng Hrê, tập các từ tiếng Việt, từ loại và các ví dụ Hrê: Việt).
Bước 2: kiểm tra từ tiếng Hrê trong KNV Hrê, nếu chưa có thì bổ sung vào.
Bước 3: đọc chỉ số của từ tiếng Hrê
Bước 4: tách từ tiếng Việt trong tập các từ tiếng Việt đọc được ở cột thứ hai của hàng trong tệp từ điển. Thực hiện lần lượt cho mỗi từ tách được:
Bước 4.1: kiểm tra từ tiếng Việt tách được trong KNV tiếng Việt, nếu chưa có thì bổ sung vào và ghi chú cho việc xác định từ mới được bổ sung vào KNV tiếng Việt.
Bước 4.2: đọc chỉ số của từ tiếng Việt
Bước 4.3: trích trong tập ví dụ các ví dụ Hrê: Việt tương ứng với từ tiếng Việt đã tách được ởbước4trongtậpvídụđọcđượcởbước1. Chuyển ví dụ Hrê: Việt thành Việt: Hrê.
Ví dụ Hrê-Việt: “Gu d’ruh Hrê ta lêu d’ha ra ngot: Cô gái Hrê hát cũng hay.” chuyển thành ví dụ Việt-Hrê: “Cô gái Hrê hát cũng hay: Gu d’ruh Hrê ta lêu d’ha ra ngot.”
Bước 4.4: kiểm tra bộ ba giá trị (chỉ số từ tiếng Việt, chỉ số từ tiếng Hrê, từ loại) trong KNV Việt-Hrê:
Nếu chưa có thì bổ sung bộ ba giá trị và các ví dụ Việt: Hrê có được từ bước 4.3 vào KNV Việt-Hrê.
Nếu đã có thì kiểm tra các ví dụ đã trích trong bước 4.3 trong tập các ví dụ tương ứng với bộ ba giá trị, nếu ví dụ nào chưa có thì bổ sung vào.
Bước 5: quay lại bước 1 lần lượt đọc dữ liệu trên mỗi hàng trong tệp từ điển Hrê-Việt cho đến hết.
Hoạt động của mô đun tương tác Co-Việt

Trình từ thực hiện
Bước 1: đọc dữ liệu trên mỗi hàng trong tệp từ điển Co-Việt (từ tiếng Co, tập các từ tiếng Việt, từ loại và các ví dụ Co: Việt).
Bước 2: kiểm tra từ tiếng Co trong KNV Co, nếu chưa có thì bổ sung vào.
Bước 3: đọc chỉ số của từ tiếng Hrê
Bước 4: tách từ tiếng Việt trong tập các từ tiếng Việt đọc được ở cột thứ hai của hàng trong tệp từ điển. Thực hiện lần lượt cho mỗi từ tách được:
Bước 4.1: kiểm tra từ tiếng Việt tách được trong KNV tiếng Việt, nếu chưa có thì bổ sung vào và ghi chú cho việc xác định từ mới được bổ sung vào KNV tiếng Việt.
Bước 4.2: đọc chỉ số của từ tiếng Việt
Bước 4.3: trích trong tập ví dụ các ví dụ Co: Việt tương ứng với từ tiếng Việt đã tách được ở bước 4 trong tập ví dụ đọc được ở bước 1. Chuyển ví dụ Co: Việt thành Việt: Co.
Ví dụ Co-Việt: “Tamoi Kool êp e rôt hmât chêêk?: Người Co các anh có thích đánh chiêng không?”
Chuyển thành ví dụ Việt-Co: “Người Co các anh có thích đánh chiêng không?: Tamoi Kool êp e rôt hmât chêêk?”
Bước 4.4: kiểm tra bộ ba giá trị (chỉ số từ tiếng Việt, chỉ số từ tiếng Co, từ loại) trong KNV Việt-Co: Nếuchưacóthìbổsungbộbagiátrịvàcác ví dụ Việt: Hrê có được từ bước 4.3 vào KNV Việt-Co. Nếu đã có thì kiểm tra các ví dụ đã trích trong bước 4.3 trong tập các ví dụ tương ứng với bộ ba giá trị, nếu ví dụ nào chưa có thì bổ sung vào.
Bước 5: quay lại bước 1 lần lượt đọc dữ liệu trên mỗi hàng trong tệp từ điển Hrê-Việt cho đến hết.
Hệ thống quản lý kho ngữ vựng
Viêc chia sẻ KNV cho các hoạt động nghiên cứu là điều cần thiết. Để quản lý dữ liệu trong kho ngữ vựng đề tài tập trung giải pháp sử dụng những lợi thế của việc sử dụng công nghệ Blockchain mục tiêu tạo lập một nền tảng chia sẻ, trao đổi dữ liệu an toàn, tính toàn vẹn của dữ liệu và chất lượng dữ liệu.
Blockchain và các công nghệ được cung cấp bởi blockchain có thể giải quyết những thách thức này. Hệ thống quản lý kho ngữ vựng làm sao để có thể truy cập kho ngữ vựng được xác nhận bất cứ lúc nào, có thể sử dụng dữ liệu đã lưu trữ. Đồng thời các chuyên gia ngôn ngữ dân tộc thiểu số có thể xem thông tin lưu trữ trên hệ thống, không chỉ là tra cứu từ vựng mà còn cả quá trình các mục từ được cập nhật cụ thể trong Blockchain. Viêc chia sẻ kho ngữ vựng cho các nhà nghiên cứu tiếng DTTS nói chung và tiếng Hrê, tiếng Co nói riêng dễ dàng.
Blockchain là giải pháp phù hợp để góp phần nâng cao chất lượng KNV đảm bảo chất lượng các mục từ được cập nhật vào KNV.
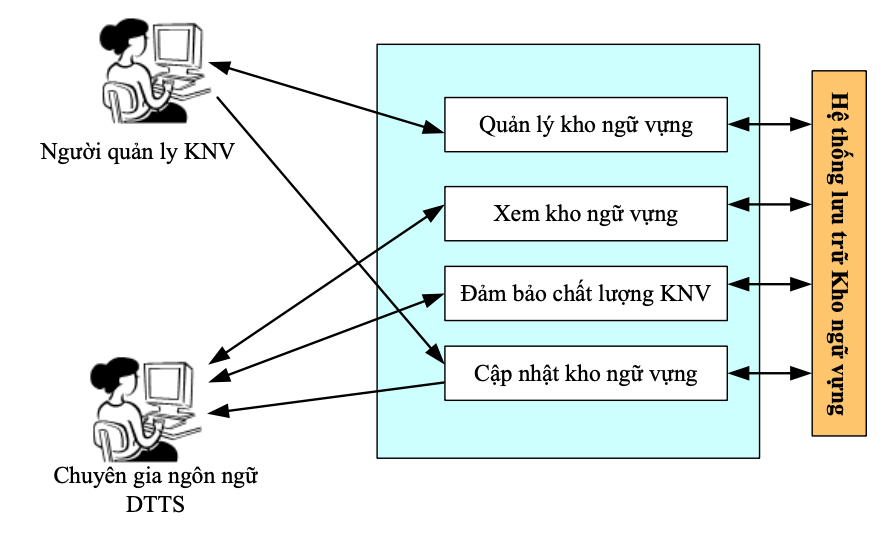
Hình 2 là một cách tiếp cận đối với sử dụng nền tảng Bảo mật, đảm bảo tính toàn vẹn của dữ liệu và chất lượng dữ liệu của KNV. Tất cả các thuộc tính bắt buộc không thể được đáp ứng bởi một cơ chế. Phạm vi quản lý KNV:
Bộ dữ liệu: là dữ liệu thực tế phải được chuyển cho các chuyên gia ngôn ngữ DTTS. Những thách thức liên quan đến việc chuyển dữ liệu thực tế là cung cấp tính toàn vẹn của dữ liệu và truyền an toàn. Một lợi thế lớn của việc sử dụng blockchain là nó có thể được sử dụng để cung cấp bằng chứng giả mạo vì bất kỳ dữ liệu nào trên blockchain là bất biến. Do đó, tính toàn vẹn của dữ liệu có thể được xác minh nếu nó nằm trên blockchain. Một khả năng là lưu các dấu thời gian của bộ dữ liệu trên blockchain để chúng không thể bị giả mạo. Dữ liệu sẽ được lưu trữ trên blockchain như thế nào và nó sẽ được chuyển đến các chuyên gia ngôn ngữ DTTS như thế đó. Việc sử dụng blockchain để truyền dữ liệu thực tế có thể hữu ích theo nhiều cách, khả năng triển khai sẽ là một phần trong công việc trong tương lai.
Chất lượng dữ liệu: chuyên gia ngôn ngữ DTTS có thể kiểm tra chất lượng dữ liệu mà không cần xem dữ liệu thực tế và người quản lý KNV cũng không thể xem yêu cầu của chuyên gia ngôn ngữ DTTS. Để kiểm tra chất lượng của bộ dữ liệu, một chức năng đảm bảo chất lượng KNV được đề xuất. Chức năng này sử dụng thực hiện kiểm tra mục từ được cập nhật trong KNV.
Kết quả thực nghiệm
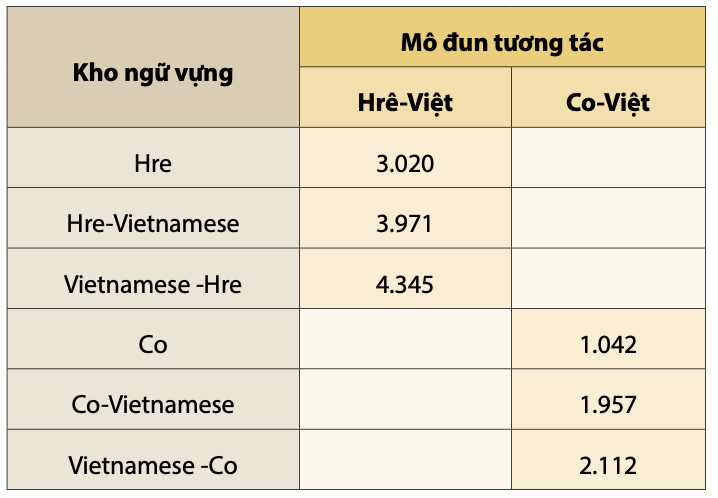
Việc cập nhật cập nhật mục từ vào các kho ngữ vựng thông qua bộ công cụ hợp nhất nguồn dữ liệu song ngữ được đề xuất xây dựng thể hiện trong Hình 3.
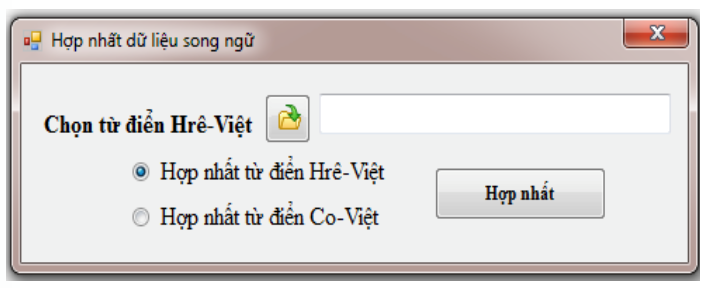
Kết quả, các mục từ được cập nhập vào trong các KNV sau khi thực hiện chuyển lần lượt các tệp từ điển Hrê-Việt và các tệp từ điển Co-Việt vào môi trường hợp nhất, được thống kê trong Bảng 2.
Kết luận
Trên cơ sở định hướng nghiên cứu xử lý tiếng DTTS Hrê và DTTS Co. Các KNV song ngữ Việt-Hrê, Hrê-Việt, Việt-Co và Co-Việt được cập nhật từ mô hình hợp nhất nguồn dữ liệu song ngữ từ điển giấy Hrê-Việt, Co-Việt được đề xuất làm hạ tầng cơ sở cho xử lý tiếng Hrê và tiếng Co. Từ cở sở hạ tầng nàCy sẽ tiếp tục phát triển các ứng dụng như tra cứu từ vựng, dịch văn bản, kiểm tra lỗi chính tả,...
Lời cảm ơn
Bài báo được thực hiện trong khuôn khổ đề tài cấp tỉnh “Xây dựng Cơ sở dữ liệu điện tử tiếng đồng bào dân tộc thiểu số Việt – Hrê, Việt – Co” do Trung tâm Công nghệ Thông tin và Truyền thông Quảng Ngãi (thuộc Sở Thông tin và Truyền thông tỉnh Quảng Ngãi) phối hợp cùng Ban dân tộc tỉnh Quảng Ngãi chủ trì thực hiện. Mã số đề tài: 03/2023/HĐ-ĐTKHCN.
-----
[1]. Đại học Sư phạm Kỹ thuật - Đại học Đà Nẵng; [2] Trung tâm CNTT-TT Quảng Ngãi - Sở TT&TT Quảng Ngãi
Tài liệu tham khảo:
1. http://www.vietlex.com/kho-ngu-lieu.
2. Nguyễn Đức Khanh. “TayNguyenKey - Chương trình hỗ trợ
gõ chữ các dân tộc thiểu số Tây Nguyên”, Sở giáo dục Đăk
Lăk,2010, địa chỉ: http://thpt-ngogiatu-daklak.edu.vn/
taynguyenkey-chuong-trinh-ho-tro-go-chu-cac-dan-toc-
thieu-so-tay-nguyen.html.
3. A. Diaz de Ilarraza, A. Gurrutxaga, I. Hernaez, N. Lopez de
Gereñu and K. Sarasola, “Integrating language engineering
resources and tools into systems with linguistic capabilities”,
Proceeding of TALN (Traitement Automatique de Langues
Naturelles), pp. 243-252, 2003.
4. Briony Williams, Mikel L. Forcada, Kepa Sarasola, “6th
SaLTMiL Workshop on: Collaboration: interoperability
between people in the creation of language resources for
less-resourced languages”, SALTMIL proceeding, Morocco,
2008.
5. Kepa Sarasola, Francis M. Tyers, Mikel L. Forcada, “7th
SaLTMiL Workshop on: Creation and use of basic lexical
resources for less-resourced languages”, Proceeding of
SALTMIL, Malta, 2010.
6. Mikel L. Forcada, Guy De Pauw, Gilles-Maurice de Schryver,
Kepa Sarasola, Francis M. Tyers, Peter Waiganjo Wagacha,
“Language technology for normalisation of less-resourced
languages”, proceeding of SALTMIL, Turkey, 2012.
7. Mikel L. Forcada, Kepa Sarasola, Francis M. Tyers, “Free/
open-Source Language Resources for the Machine
Translation of Less-Resourced Languages”, SALTMIL
procceding, Iceland, 2014.
(Bài viết đăng ấn phẩm in Tạp chí TT&TT số 10 tháng 10/2024)















.jpg "Bộ Khoa học và Công nghệ trao quyết định bổ nhiệm, bổ nhiệm lại lãnh đạo 8 đơn vị")

.jpg "Bizfly Cloud LMS - Nền tảng e-learning dễ dàng cho mọi quy mô học tập")




