
ChatGPT: Kỷ nguyên mới trong xử lý ngôn ngữ tự nhiên với các mô hình ngôn ngữ lớn
Khả năng hiểu ngôn ngữ của con người và sáng tạo ra những văn bản giống với cách con người thực hiện là mục tiêu lâu dài của nghiên cứu trí tuệ nhân tạo (Artificial Intelligence - AI). Với sự ra đời của các mô hình ngôn ngữ lớn (Large Language Model - LLM), mục tiêu đó đang gần với hiện thực hơn bao giờ hết.
ChatGPT, một mô hình AI đàm thoại (conversational AI) do OpenAI phát triển, ra mắt ngày 30/11/2022 đại diện cho một kỷ nguyên mới trong xử lý ngôn ngữ tự nhiên (Natural Language Processing - NLP) thông qua việc sử dụng các mô hình ngôn ngữ lớn này.
Khi công nghệ tiếp tục định hình và tác động đến cuộc sống hàng ngày của chúng ta, việc xử lý ngôn ngữ tự nhiên ngày càng cần thiết. Từ dịch vụ khách hàng đến dịch thuật ngôn ngữ, tóm tắt văn bản, trả lời câu hỏi (Q&A), tạo văn bản sáng tạo, NLP đang đóng một vai trò ngày càng quan trọng trong việc nâng cao hiệu quả hoạt động của người lao động và tạo điều kiện thuận lợi cho sự tương tác giữa con người với máy tính. ChatGPT đưa sự tương tác này lên một tầm cao mới, cho phép giao tiếp trực quan và liền mạch hơn với các hệ thống máy tính.
Về cốt lõi, ChatGPT là một mô hình AI đàm thoại mạnh mẽ, tận dụng điểm mạnh của các mô hình ngôn ngữ lớn để đưa ra các phản hồi, trả lời các câu hỏi, gợi ý giống như con người trong thời gian thực. Không giống như các chatbot truyền thống bị giới hạn bởi các phản hồi được lập trình sẵn, ChatGPT có thể hiểu và tạo ra vô số loại văn bản có tính sáng tạo và đôi khi cũng không hoàn toàn chính xác. Điều này mở ra những tiềm năng ứng dụng cho các doanh nghiệp (DN) và ngành công nghiệp dựa vào NLP để tương tác với khách hàng cung cấp các trải nghiệm tốt nhất và cá nhân hóa các trải nghiệm này.
Bài viết này không có tham vọng đi sâu vào các chi tiết kỹ thuật ChatGPT và các mô hình ngôn ngữ lớn, nhưng sẽ phác họa những những tiến bộ đã giúp LLM trở nên khả thi và tác động của chúng đối với lĩnh vực NLP. Từ dịch vụ khách hàng được cải thiện đến các ứng dụng mới và sáng tạo, chúng ta sẽ xem xét các khả năng thú vị mà các mô hình này đang tạo ra. Ngoài ra, chúng ta sẽ thảo luận về những thách thức và hạn chế mà lĩnh vực này vẫn phải đối mặt, cung cấp một cái nhìn tổng quan cân bằng và toàn diện về tình trạng của NLP trong kỷ nguyên ChatGPT, khám phá tương lai của NLP và vai trò của ChatGPT trong việc định hình nó.
Sơ nét về ChatGPT
Nếu bạn hỏi ChatGPT là gì, đây là những gì chatbot tiên tiến này sẽ cho bạn biết: "ChatGPT là một mô hình ngôn ngữ AI do OpenAI phát triển, có khả năng tạo văn bản giống con người dựa trên đầu vào được cung cấp. Mô hình này được huấn luyện trên một kho dữ liệu văn bản lớn và có thể tạo câu trả lời cho các câu hỏi, tóm tắt văn bản dài, viết truyện và hơn thế nữa. ChatGPT thường được sử dụng trong các ứng dụng AI đàm thoại để mô phỏng cuộc trò chuyện giống con người với người dùng." [1]

ChatGPT là một mô hình AI đàm thoại tiên tiến, được OpenAI phát triển và ra mắt vào cuối tháng 11/2022. OpenAI đã huấn luyện mô hình này bằng cách sử dụng kỹ thuật học tăng cường từ phản hồi của con người (Reinforcement Learning from Human Feedback - RLHF) [2], sử dụng các phương pháp tương tự như InstructGPT, nhưng có một số khác biệt nhỏ trong thiết lập thu thập dữ liệu.[3]

Một trong những tính năng chính của ChatGPT là sử dụng các mô hình ngôn ngữ lớn. Các mô hình này được huấn luyện (training) trên một lượng lớn 530 GB dữ liệu văn bản trên mạng từ sách báo, Wekipedia, các thông tin website, các văn bản do Open AI tự thu thập. Số lượng dữ liệu khổng lồ này giúp ChatGPT hiểu và tạo ra một loạt các mẫu và phong cách ngôn ngữ khác nhau. Với các huấn luyện từ trước (pre-training), ChatGPT đưa ra phản hồi không chỉ chính xác mà còn giống con người về giọng điệu và cách thức.
Các chatbot trước đây không sử dụng AI. Một số chatbot chỉ đơn giản sử dụng từ khóa để tạo phản hồi. Không giống như các chatbot truyền thống bị giới hạn bởi các phản hồi được lập trình sẵn, ChatGPT có thể tạo các phản hồi mới và độc đáo trong thời gian thực. Điều này có nghĩa là ChatGPT không chỉ có khả năng trả lời các câu hỏi đơn giản mà còn có thể tham gia vào các cuộc trò chuyện phức tạp và nhiều sắc thái, mang lại trải nghiệm giống con người hơn cho người dùng.
Tuy nhiên, lợi ích của ChatGPT không chỉ mang lại trải nghiệm giống con người hơn. Các khả năng NLP nâng cao của mô hình làm cho nó trở thành một công cụ mạnh mẽ cho các doanh nghiệp (DN) và tổ chức dựa vào giao tiếp dựa trên văn bản. Với ChatGPT, các nhóm dịch vụ khách hàng có thể cung cấp hỗ trợ hiệu quả và hiệu quả hơn, trong khi các tác vụ dịch thuật và tạo ngôn ngữ có thể được thực hiện với độ chính xác và tốc độ cao.
ChatGPT đã thiết lập những kỷ lục mới trong lịch sử các công nghệ được chào đón nhiệt nhiệt trong một thời gian ngắn. Chỉ sau 5 ngày ra mắt, ứng dụng AI này đã đạt con số 1 triệu người dùng. Sau 2 tháng thử nghiệm, đã có 100 triệu khách truy cập, theo phân tích của công ty dữ liệu Similarweb. Tiktok một ứng dụng phát triển nhanh cũng phải mất 2 năm mới đạt số lượng người dùng tương đương. Các nhà phân tích tại ngân hàng đầu tư UBS cho biết tốc độ tăng trưởng chưa từng có đối với một ứng dụng. [5]
Một số người coi ChatGPT là mối đe dọa trực tiếp đối với hoạt động kinh doanh công cụ tìm kiếm trị giá 149 tỷ USD của Google, lĩnh vực mà Google đã dẫn đầu trong nhiều năm. Microsoft gần đây đã xác nhận mở rộng quan hệ đối tác với OpenAI, đi kèm với khoản đầu tư 10 tỷ USD. [6]
Các mô hình ngôn ngữ lớn
Các mô hình ngôn ngữ lớn đã trở thành động lực đằng sau những tiến bộ gần đây trong xử lý ngôn ngữ tự nhiên (NLP). Các mô hình này có khả năng hiểu và tạo ra ngôn ngữ của con người ở cấp độ ngày càng cao. Trước đây, các mô hình NLP bị giới hạn bởi bộ dữ liệu huấn luyện nhỏ và độ phức tạp của các thuật toán mà chúng sử dụng. Điều này thường dẫn đến các mô hình bị hạn chế về khả năng và dễ bị lỗi. Tuy nhiên, với sự ra đời của các mô hình ngôn ngữ lớn, tất cả đã thay đổi.
Bằng cách huấn luyện trên một lượng lớn dữ liệu văn bản, các LLM có thể tìm hiểu những điểm phức tạp và tinh tế của ngôn ngữ con người ở quy mô lớn. Điều này đã cho phép các mô hình NLP vượt ra ngoài các hệ thống dựa trên quy tắc đơn giản (rule based) sang các phương pháp tiếp cận dựa trên dữ liệu, nâng cao hơn. Lượng văn bản khổng lồ như vậy được đưa vào thuật toán AI bằng cách sử dụng phương pháp học không giám sát (unsupervised learning) - khi một mô hình được cung cấp một tập dữ liệu mà không có hướng dẫn rõ ràng về việc phải làm gì với dữ liệu. Thông qua phương pháp này, một mô hình ngôn ngữ lớn học các từ, cũng như các mối quan hệ giữa chúng và các khái niệm đằng sau chúng.
Và giống như một người thông thạo một ngôn ngữ có thể đoán điều gì có thể xảy ra tiếp theo trong một câu hoặc đoạn văn hoặc thậm chí tự mình nghĩ ra các từ hoặc khái niệm mới, một mô hình ngôn ngữ lớn có thể áp dụng kiến thức của mình để dự đoán và tạo nội dung. [7]
Các mô hình ngôn ngữ lớn cũng có thể được tùy chỉnh cho các trường hợp sử dụng cụ thể, bao gồm thông qua các kỹ thuật như tinh chỉnh (fine-tuning), đây là quá trình cung cấp cho mô hình các dữ liệu nhỏ, nhằm huấn luyện mô hình cho một ứng dụng cụ thể. Các mô hình được huấn luyện sẵn (pre-trained model) thường chỉ huấn luyện các dữ liệu, kiến thức mang tính tổng quan. Để ứng dụng LLM vào các lĩnh vực chuyên sâu như y khoa, dược phẩm, luật học, cần các kỹ thuật tinh chỉnh với kho dữ liệu đặc thù của những chuyên ngành này.
Kích cỡ của các mô hình ngôn ngữ lớn
Khi nói đến sức mạnh của LLM, người ta hay nói về tham số (thông số) (parameters):
GPT-1 (6/2018) - được huấn luyện trên 117 triệu tham số
GPT-2 (11/2019) - được huấn luyện trên 1,2 tỷ tham số
GPT-3 (6/2020) - được huấn luyện trên 175 tỷ tham số
GPT-3.5 (3/2022) - được huấn luyện trên 175 tỷ tham số
BLOM (7/2022) ) - được huấn luyện trên 176 tỷ tham số
PaLM-coder Miverva (4/2022) - được huấn luyện trên 540 tỷ tham số và là mô hình ngôn ngữ lớn có kích cỡ về tham số lớn nhất tính đến thời điểm hiện tại.
Người ta ước chừng kích cỡ của tham số mô hình (model size) tăng gấp 10 lần mỗi năm.
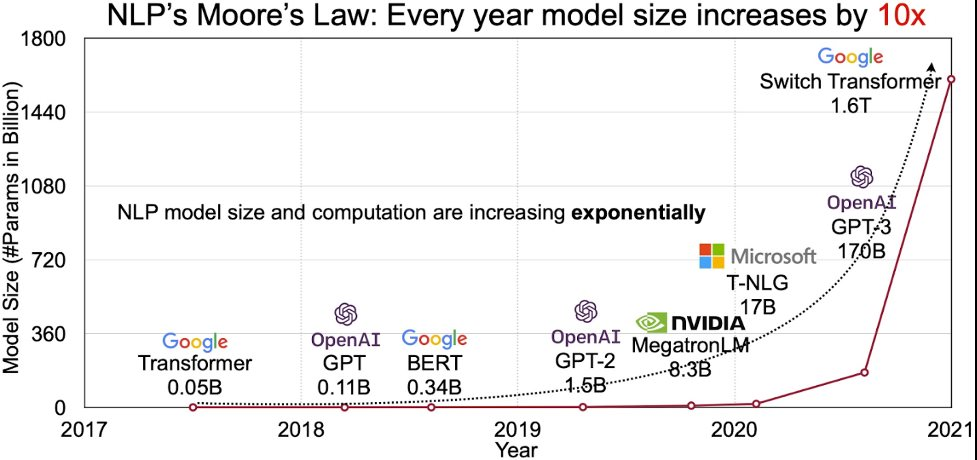
Các tham số, còn được gọi là "weight" (trọng số), có thể được coi là kết nối giữa các điểm dữ liệu được tạo trong quá trình huấn luyện trước (pre-trained). Các tham số cũng được so sánh với các khớp thần kinh não người, các kết nối giữa các tế bào thần kinh của chúng ta. Não người có khoảng 86 tỷ tế bào thần kinh, mỗi tế bào thần kinh nối đến 15.000 tế bào khác và tổng cộng có khoảng 100.000 tỷ (100 trillions) các kết nối. Mạng neuron nhân tạo vẫn còn kém xa số kết nối giữa các neuron ở người.
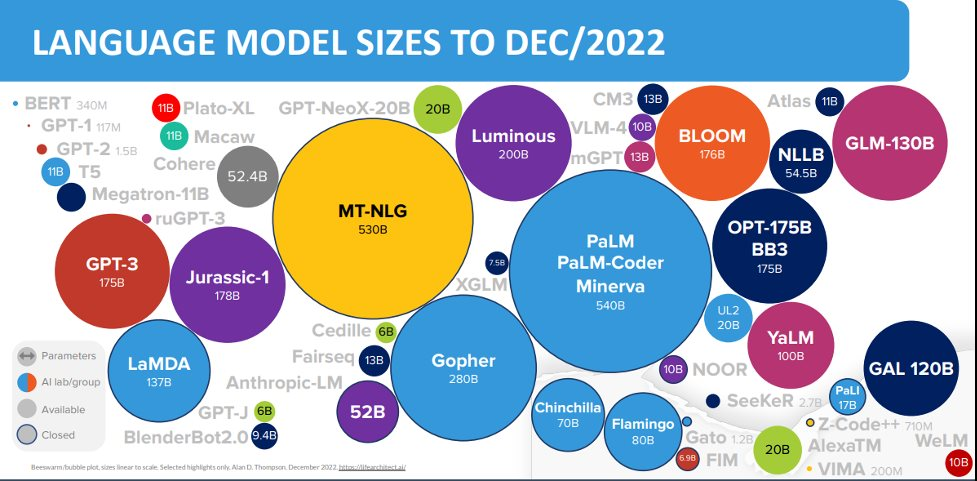
Tuy nhiên, tham số không phải là tất cả. "Lớn hơn là tốt hơn” không phải là động lực chính của các mô hình huấn luyện từ trước (pre-trained model), vì mô hình Chinchilla (70 tỷ tham số) vượt trội so với Gopher (280 tỷ tham số).
Sức mạnh của ChatGPT
Được xây dựng với sự cộng tác và dành riêng cho OpenAI, siêu máy tính được lưu trữ trong Azure được thiết kế đặc biệt để đào tạo các mô hình AI của công ty đó. Siêu máy tính của OpenAI dùng để huấn luyện mô hình GPT-3 là một hệ thống duy nhất có hơn 285.000 lõi CPU, 10.000 GPU [giả sử GPU NVIDIA Tesla V100 được phát hành vào tháng 5/2017, được thay thế bởi GPU NVIDIA Ampère A100 vào tháng 5/2020 và 400 gigabit trên mỗi giây (Gbps) của kết nối mạng cho mỗi máy chủ GPU. [9]
Với hơn 300 ứng dụng hiện đang sử dụng GPT-3 và hàng chục nghìn nhà phát triển trên toàn cầu đang xây dựng trên nền tảng của OpenAI. Các nền tảng GPT-3 hiện tạo ra trung bình 4,5 tỷ từ/ngày và tiếp tục mở rộng quy mô lưu lượng sản xuất. Trung bình 55.000 từ/cuốn sách, hệ thống GPT-3 của Open AI đang tạo ra số lượng từ vào khoảng tương đương 81.818 cuốn sách/ngày. Năm 2017, có 9.045 thư viện công cộng ở Hoa Kỳ với tổng số 732 triệu cuốn sách [10], như vậy, sản lượng văn bản sản xuất (generative text) của GPT-3 trong 1 ngày bằng tổng số sách trong thư viện công cộng Hoa Kỳ.
Với sức mạnh tính toán vượt trội, ChatGPT có chỉ số IQ được kiểm tra là 147 trong bài kiểm tra IQ ngôn ngữ. Người trung bình có IQ là 120. Về mặt ngôn ngữ ChatGPT có khả năng hơn nhiều người chúng ta. Công cụ trí tuệ nhân tạo ChatGPT gần đây đã vượt qua được các bài kiểm tra của 4 khóa học tại Đại học Minnesota và một kỳ thi khác tại Trường Kinh doanh Wharton của Đại học Pennsylvania.

Một số ứng dụng của mô hình ngôn ngữ lớn
Các mô hình ngôn ngữ lớn đang mở ra những khả năng mới trong các lĩnh vực như công cụ tìm kiếm, xử lý ngôn ngữ tự nhiên, chăm sóc sức khỏe, người máy và tạo mã máy tính (coding).
Chatbot AI ChatGPT là một ứng dụng của mô hình ngôn ngữ lớn. LLM có thể được sử dụng cho vô số tác vụ xử lý ngôn ngữ tự nhiên. Các ứng dụng cho LLM cũng thể kể bao gồm [7]:
- Các nhà bán lẻ và các nhà cung cấp dịch vụ khác có thể sử dụng các mô hình ngôn ngữ lớn để cung cấp trải nghiệm khách hàng được cải thiện thông qua chatbot động, trợ lý AI, v.v.
- Các công cụ tìm kiếm có thể sử dụng các mô hình ngôn ngữ lớn để cung cấp các câu trả lời trực tiếp hơn, giống con người hơn.
- Các nhà nghiên cứu khoa học đời sống có thể đào tạo các mô hình ngôn ngữ lớn để hiểu protein, phân tử, DNA và RNA.
- Các nhà phát triển có thể viết phần mềm và dạy robot các nhiệm vụ vật lý bằng các mô hình ngôn ngữ lớn.
- Các nhà tiếp thị có thể đào tạo một mô hình ngôn ngữ lớn để tổ chức phản hồi và yêu cầu của khách hàng thành các cụm hoặc phân chia sản phẩm thành các danh mục dựa trên mô tả sản phẩm.
- Cố vấn tài chính có thể tóm tắt các cuộc gọi thu nhập và tạo bản ghi các cuộc họp quan trọng bằng cách sử dụng các mô hình ngôn ngữ lớn. Và các công ty thẻ tín dụng có thể sử dụng LLM để phát hiện bất thường và phân tích gian lận để bảo vệ người tiêu dùng.
- Các nhóm pháp lý có thể sử dụng các mô hình ngôn ngữ lớn để giúp diễn giải và viết phác thảo pháp lý sau đó kiểm tra lại.
Hạn chế và những thách thức của LLM
Các mô hình ngôn ngữ lớn (LLM) có tiềm năng cách mạng hóa lĩnh vực NLP (xử lý ngôn ngữ tự nhiên), nhưng việc phát triển và triển khai những mô hình này là một thách thức. Việc mở rộng quy mô và duy trì LLM thường khó khăn và đòi hỏi chuyên môn kỹ thuật, nguồn lực và đầu tư đáng kể.
Quá trình xây dựng một mô hình ngôn ngữ lớn nền tảng có thể mất vài tháng và cần đầu tư hàng triệu USD. Điều này là do kích thước và độ phức tạp tuyệt đối của các mô hình này, đòi hỏi một lượng lớn dữ liệu đào tạo để thực hiện chính xác.
Việc truy cập lượng dữ liệu này cũng có thể là một thách thức vì các nhà phát triển và DN có thể gặp khó khăn trong việc tìm kiếm các bộ dữ liệu đủ lớn.
Ngoài ra, việc triển khai LLM đòi hỏi sự hiểu biết sâu sắc về học sâu, mô hình học sâu transformer, phần mềm và phần cứng phân tán. Chuyên môn kỹ thuật này là cần thiết để đảm bảo rằng các mô hình này hoạt động như dự định và có thể đáp ứng nhu cầu của các ứng dụng trong thế giới thực. Mặt khác, khi đào tạo các mô hình lớn như vậy, các nhóm khác nhau với chuyên môn đa dạng phải hợp tác để chạy thử nghiệm, xây dựng và duy trì cơ sở hạ tầng máy tính, phát triển thuật toán và liên tục thẩm vấn các khả năng của mô hình đối với các vấn đề có thể xảy ra như sai lệch, lạm dụng, an toàn, v.v. .
Một số tính toán rất thô sơ ước tính chi phí huấn luyện mô hình ít nhất là 4,6 triệu USD [11], [12] với 3.14 e23 FLOPs (dùng 28 TFLOPS GPU V100, mất 355 năm) khi sử dụng nhà cung cấp đám mây GPU rẻ nhất, điều này nằm ngoài khả năng của hầu hết các công ty, đó là chưa bao gồm chi phí R&D, có thể dễ dàng đưa tổng chi phí lên tới hơn 35 triệu USD trong trường hợp huấn luyện AlphaGo Zero năm 2017 [11]. Để huấn luyện một GPT có số lượng tham số giống số lượng synapes (nơi tiếp xúc giữa hai nơron, mà thông qua đó cho phép các nơron truyền đi thông tin qua lại lẫn nhau (100.000 tỷ (trillions)) như con người có thể lên đến 2,6 tỷ USD theo ước tính của Lex Fridman. Đây là điều mà các công ty nhỏ hơn không thể cạnh tranh được.
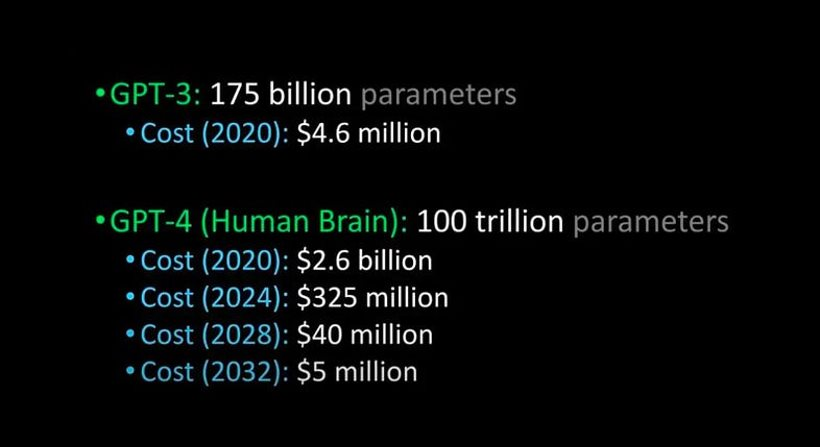
LLM và GPT-3 có thể thể hiện một số thành kiến về chủng tộc, giới tính và tôn giáo. Mặc dù có những quy định và các biện pháp kỹ thuật nhưng việc này tương đối khó khăn. Một số người ý kiến cho rằng việc giảm thiểu sai lệch cho các hệ thống đa mục đích như GPT-3 thông qua các thay đổi đối với dữ liệu đào tạo của chúng là rất khó vì sai lệch thường được phân tích trong ngữ cảnh của một trường hợp sử dụng cụ thể.
Những người tham gia hội thảo tại “Viện trí tuệ nhân tạo lấy con người làm trung tâm Stanford” (Stanford Institute for Human-Centered Artificial Intelligence) bao gồm các nhà nghiên cứu khoa học máy tính, ngôn ngữ học, triết học, khoa học chính trị, truyền thông, chính sách mạng đã đưa ra nhiều phương pháp khả thi để giải quyết những thành kiến có hại trong các mô hình ngôn ngữ: [14]:
- Thay đổi dữ liệu đào tạo ban đầu để giảm thiểu sai lệch tiên nghiệm (a priori bias).
- Đào tạo một mô hình riêng biệt để lọc nội dung do mô hình ngôn ngữ tạo ra.
- Tinh chỉnh mô hình ngôn ngữ lớn trên dữ liệu với các thuộc tính mong muốn.
- Gắn thẻ dữ liệu để mô hình học cách phân biệt giữa các dạng nội dung nhất định.
- Các mô hình đào tạo trở nên “nhận biết dữ kiện” (fact-aware)
- Học tăng cường với phản hồi của con người
- Tận dụng kiến thức của chính mô hình để cải thiện kết quả đầu ra
LLM nói riêng và AI nói chung đang chuyển đổi các ngành công nghiệp như thế nào?
Dưới đây là một số ngành bị ảnh hưởng bởi công cụ AI tiên tiến mới này [6]:
Công cụ tìm kiếm (search engine)
Các nhà quản lý của Google đã tuyên bố tình trạng khẩn cấp (Code red - Mã đỏ) khi ChatGPT được phát hành. Google thống trị trong lĩnh vực kinh doanh công cụ tìm kiếm trong hơn hai thập kỷ qua. Người ta lo ngại rằng người dùng sẽ chuyển sang chatbot để được trợ giúp thay vì phải tự mình tìm thông tin qua hàng ngàn link trong các trang web do Google cung cấp. Mặt khác, ChatGPT còn cung cấp phản hồi nhanh chóng và trực tiếp cho các vấn đề cụ thể, ngay cả khi các câu hỏi phức tạp. Tất nhiên, công cụ tìm kiếm sẽ không biến mất vì người ta cần những sở cứ cho các vấn đề mình cần trong khi tại thời điểm hiện tại, ChatGPT tạo ra cái gọi là “sáng tạo” văn bản, tạo nên những “ảo giác” (halluciations) hay thậm chí bịa đặt (Confabulation) những sở cứ khi lập luận. Mô hình Generative AI sẽ là một sự bổ sung cho các công cụ tìm kiếm trong tương lai.
Microsoft đã dự trù kết hợp kỹ thuật do ChatGPT cung cấp để cải thiện công cụ tìm kiếm Bing của mình. Google có kế hoạch phát hành 20 sản phẩm AI mới và chia sẻ một phiên bản công cụ tìm kiếm có tính năng chatbot. Vấn đề lớn nhất của Google là mô hình kinh doanh với khoảng 80% doanh thu vẫn đến từ quảng cáo. Google cũng lo lắng về sự an toàn, thông tin sai lệch và tính chính xác của chatbot.
Hệ thống giáo dục
Có những lo ngại từ các giáo viên về đạo văn vì chatbot có thể viết một bài luận hoặc tạo tác phẩm từ một vài lời nhắc đơn giản. Nhiều giáo viên đã bày tỏ lo lắng về ý nghĩa của điều này đối với hệ thống giáo dục. Một số trường đã cấm công cụ này, trong khi những trường khác đang cân nhắc cách đưa nó vào lớp học.
Giada Pistilli, nhà đạo đức học làm việc tại Hugging Face, giải thích thách thức mà các cơ sở giáo dục gặp phải với ChatGPT: “Thật không may, hệ thống giáo dục dường như buộc phải thích nghi với những công nghệ mới này. Tôi nghĩ đó là một phản ứng có thể hiểu được, vì chưa có nhiều việc được thực hiện để dự đoán, giảm thiểu hoặc xây dựng các giải pháp thay thế nhằm giải quyết các vấn đề về AI có thể xảy ra. Các công nghệ đột phá thường yêu cầu giáo dục người dùng bởi vì hông thể đơn giản là ném AI vào mọi người một cách không kiểm soát được.”
Theo GS. Đào Triết Hiên (Terence Tao), nhà toán học tài năng người Mỹ gốc Trung Quốc, giành Huy chương Fields năm 2016: "Về lâu dài, chống lại điều này dường như là vô ích; có lẽ những gì chúng ta cần làm với tư cách là giảng viên là chuyển sang chế độ kiểm tra “sách mở, AI mở” ("Open book, Open AI")".
Thiết kế đồ họa
Nhiều người lo lắng rằng người dùng sẽ sử dụng các công cụ nghệ thuật do AI cung cấp để tạo tác phẩm nghệ thuật và đồ họa thay vì thuê các nhà thiết kế đồ họa. Những công cụ tạo hình vẽ từ những văn bản (text-to-image), một họ ứng dụng của LLM như DALL·E 2, Mid Journey, Stable Diffusion làm dấy lên những lo ngại về đạo đức và pháp lý đối với quyền sở hữu. Mặc dù công nghệ tạo đồ họa vẫn đang ở giai đoạn đầu, nhưng tiềm năng của những công nghệ này rất lớn.
Lĩnh vực nghiên cứu
Những chatbot được hỗ trợ bởi AI này sẽ trở thành công cụ hỗ trợ có giá trị với các hoạt động nghiên cứu. Thay vì lọc qua các công cụ tìm kiếm, nhà nghiên cứu có thể tìm thấy thông tin liên quan bằng cách nhập văn bản đơn giản. Có thể sử dụng chatbot để tự động hóa và đơn giản hóa các tác vụ cụ thể trong quá trình nghiên cứu như tạo văn bản tóm tắt tài liệu, gợi ý các lập luận, viết đề cương phác thảo cho các ý tưởng mới.
Tác động của các mô hình ngôn ngữ lớn vượt ra ngoài sự tưởng tượng. Những mô hình này có tiềm năng cách mạng hóa nhiều ngành công nghiệp, từ tài chính và chăm sóc sức khỏe đến giải trí và hơn thế nữa. Với khả năng hiểu và tạo ra ngôn ngữ của con người, các mô hình ngôn ngữ lớn được thiết lập để đóng vai trò chính trong việc định hình tương lai của AI và công nghệ nói chung.
Tóm lại, ChatGPT đại diện cho một kỷ nguyên mới trong xử lý ngôn ngữ tự nhiên thông qua việc sử dụng các mô hình ngôn ngữ lớn. Những tiến bộ của LLM mà đại diện là ChatGPT trong việc tạo và dịch ngôn ngữ đã mở ra những khả năng mới cho các ứng dụng sáng tạo. Tuy nhiên, như với bất kỳ công nghệ mạnh mẽ nào, cũng có những thách thức và hạn chế, bao gồm các mối lo ngại về đạo đức và nhu cầu giám sát và phát triển liên tục để đảm bảo kết quả công bằng và chính xác. Bất chấp những thách thức này, tương lai của ChatGPT và các mô hình ngôn ngữ lớn trong NLP vẫn rất tươi sáng và chúng ta có thể mong đợi những tiến bộ và đổi mới liên tục trong lĩnh vực này. Để nhận ra đầy đủ tiềm năng của công nghệ này, các nhà nghiên cứu và lãnh đạo ngành nên hợp tác với nhau để vượt qua những thách thức và hạn chế, đồng thời tiếp tục khám phá khả năng của các mô hình ngôn ngữ lớn.
Tài liệu tham khảo:
[1] Mashable, “What is ChatGPT? Everything you need to know about the AI chatbot,” 2023. https://mashable.com/article/w... (accessed Feb. 05, 2023).
[2] L. Gao, J. Schulman, and J. Hilton, “Scaling Laws for Reward Model Overoptimization,” Oct. 2022, Accessed: Feb. 05, 2023. [Online]. Available: https://openai.com/blog/chatgp...
[3] Open AI, “ChatGPT: Optimizing Language Models for Dialogue,” 2022. https://openai.com/blog/chatgp... (accessed Feb. 05, 2023).
[4] D. A. D. Thompson, “Inside language models (from GPT-3 to PaLM),” Life Architect, 2022. https://lifearchitect.ai/model... (accessed Feb. 05, 2023).
[5] the Guardian, “ChatGPT reaches 100 million users two months after launch | Chatbots | The Guardian,” 2023. https://www.theguardian.com/te... (accessed Feb. 05, 2023).
[6] Forbes, “What Is ChatGPT? How AI Is Transforming Multiple Industries,” 2023. https://www.forbes.com/sites/q... (accessed Feb. 05, 2023).
[7] Nvidia, “What Are Large Language Models Used For and Why Are They Important? | NVIDIA Blog,” 2023. https://blogs.nvidia.com/blog/... (accessed Feb. 05, 2023).
[8] India AI, “The Future of Large Language Models (LLMs): Strategy, Opportunities and Challenges,” 2023. https://indiaai.gov.in/article... (accessed Feb. 05, 2023).
[9] Microsoft, “Microsoft announces new supercomputer, lays out vision for future AI work - Source,” 2020. https://news.microsoft.com/sou... (accessed Feb. 05, 2023).
[10] National Center for Education Statistics, “Number of public libraries, number of books and serial volumes, and per capita usage of selected library services per year, by state: Fiscal years 2015 and 2016,” 2017. https://nces.ed.gov/programs/d... (accessed Feb. 05, 2023).
[11] “[D] GPT-3, The $4,600,000 Language Model : MachineLearning,” Reddit, 2019. https://www.reddit.com/r/Machi... (accessed Feb. 05, 2023).
[12] Chuan Li, “OpenAI’s GPT-3 Language Model: A Technical Overview,” 2020. https://lambdalabs.com/blog/de... (accessed Feb. 05, 2023).
[13] Lex Fridman, “(7) GPT-3 vs Human Brain,” Youtube, 2020. https://www.youtube.com/watch?... (accessed Feb. 05, 2023).
[14] A. Tamkin, M. Brundage, J. C. †3, and D. Ganguli, “Understanding the Capabilities, Limitations, and Societal Impact of Large Language Models,” Feb. 2021, doi: 10.48550/arxiv.2102.02503.
(Bài đăng ấn phẩm in Tạp chí TT&TT số 2 tháng 2/2023)





















